Businesses of mid and large scale have massive amounts of printed documents in daily use. Among them are invoices, receipts, corporate documents, reports, media releases. And millions of them can be handwritten, which makes documents understandable for humans but difficult to read for machines.
Basic Concept of OCR
Optical character recognition (OCR) algorithms allow computers to analyze printed or handwritten documents automatically and prepare text data into editable formats for computers to efficiently process them. It is another way to extract and leverage business-critical data. According to the International Institute of Analytics, businesses using data can get a competitive advantage and see $430 billion in productivity benefits by the year 2020.

Source: https://www.techradar.com/
How It Works
Human eyes naturally recognize various patterns, fonts or styles. For computers, it is hard work to do. Any scanned document is a graphics file, i.e., a pattern of pixels. A computer localizes, detects and recognizes characters on an image and turns the image of paper documents into a text file.
Then, it becomes possible to extract meaningful information. Texts in a machine-readable form can then be used for different purposes. They can be scanned in search of patterns and vital data, used to generate reports and draw up charts, distributed into spreadsheets, and more.
6 Steps to Build an OCR Engine
Building an OCR engine from scratch, like those that InData Labs’ OCR experts work on, is a step-by-step process. The development process usually encompasses 6 steps needed to train an algorithm for efficient problem-solving with the help of optical character recognition.
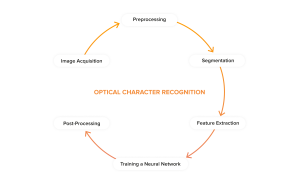
1. Image Acquisition
The first step is to acquire images of paper documents with the help of optical scanners. This way, an original image can be captured and stored. Most of the paper documents are black and white, and an OCR scanner should be able to threshold images. In other words, it should replace each pixel in an image with a black or a white pixel. It is a method of image segmentation.
2. Preprocessing
The goal of preprocessing is to make raw data usable by computers. The noise level on an image should be optimized and areas outside the text removed. Preprocessing is especially vital for recognizing handwritten documents that are more sensitive to noise. Preprocessing allows obtaining a clean character image to yield better results of image recognition.
3. Segmentation
The process of segmentation is aimed at grouping characters into meaningful chunks. There can be predefined classes for characters. So, images can be scanned for patterns that match the classes.
4. Feature Extraction
This step means splitting the input data into a set of features, that is, to find essential characteristics that make one or another pattern recognizable. As a result, each character gets classified in a particular class.
5. Training a Neural Network
Once all the features are extracted, they can be fetched to a neural network (NN) to train it to recognize characters. A training dataset and the methods applied to achieve the best output will depend on a problem that requires an OCR-based solution.
6. Post-Processing
This stage is the process of refinement as an OCR model can require some corrections. However, it isn’t possible to achieve 100% recognition accuracy. The identification of characters heavily depends on the context. The verification of the output requires a human-in-the-loop approach.
Technologies Under the Hood
The performance of OCR models draws on multilayer artificial neural networks. For computer vision, the most common types are recurrent neural networks (RNN) or more precisely long short-term memory (LSTM), and convolutional neural networks (CNN).
The working principle of RNN is to save the output of a layer and then feed it back as the input. Such architecture makes it easy to predict the outcome of the layer.
CNN is a feedforward type of neural networks. The information flows through the network, and the output of the model isn’t used again as the input. The usage of one or another type of NN is determined by a problem to solve.
Customer challenges don’t always require building an OCR engine from scratch. An out-of-the-box framework Tesseract enables excellent capabilities to train neural networks. It provides ready-to-use NN-based models and allows engineers with deep know-how to train custom OCR algorithm.
To facilitate image processing, tools from OpenCV may come in handy. It is an open-source library that provides different computer algorithms. Another solution, powered by Google, is the Vision API that offers pre-trained models to extract text from images of different type and quality.

Source: https://cloud.google.com
Make It to Efficient Document Management
Businesses worldwide employ OCR to capture and process data from paper documents. It comes as a necessity every time a consumer can use a smartphone for validation. A good example is using OCR in dedicated ticket scanners at concerts or festivals. Likewise, the technology can be used for access control by scanning ID cards and passports in airport and railway stations. Be it a car rental or parking services, using OCR is a handy way to eliminate unnecessary paper flow.

Source: https://www.adobe.com/
OCR can assist in improving the level of security when it comes to verifying the authenticity of goods. It can be used for checking goods using infrared scanners. The retrieved data on infrared marks can then be run through a database.
The automation of many mundane processes within an organization can become possible with OCR. In the finance and insurance area, employees have to deal with millions of receipts and invoices. An optical character recognition algorithm can help digitize, classify, store and spread such types of documents several times more effective.
On a Final Note
The usage of OCR makes it easy to meet in-house document standards, give a head start to workflow automation, fully or partially eliminate the need for paper workflow. High-level optical character recognition services can assist many mid- and large-scale companies to make a profit from using custom-tailored algorithms. Industries like banking and finance, healthcare, tourism, and logistics may benefit the most from the successful implementation of OCR.