
The mission of artificial intelligence (AI) is to assist humans in processing large amounts of analytical data and automate an array of routine tasks. Despite various challenges in natural language processing, powerful data can facilitate decision-making and put a business strategy on the right track. But first, somebody should harvest useful data from multiple sources.
Managing documents traditionally involves many repetitive tasks and requires much of the human workforce. As an example, the know-your-client (KYC) procedure or invoice processing needs someone in a company to go through hundreds of documents to handpick specific information.
AI can automate document flow, reduce the processing time, save resources – overall, become indispensable for long-term business growth and tackle challenges in NLP.
Sped up by the pandemic, automation will further accelerate through 2021 and beyond transforming business internal operations and redefining management.
Is intelligent process automation already a part of your business strategy? If not, you’d better take a hard look at how AI-based solutions address the challenges of text analysis and data retrieval.
Understanding NLP and OCR Processes
Optical character recognition (OCR) is the core technology for automatic text recognition. With the help of OCR, it is possible to translate printed, handwritten, and scanned documents into a machine-readable format. The technology relieves employees of manual entry of data, cuts related errors, and enables automated data capture.
What are OCR challenges and solutions to that? The functions of OCR-based solutions are not limited to mere recognition. Such solutions provide data capture tools to divide an image into several fields, extract different types of data, and automatically move data into various forms, CRM systems, and other applications.
Information in documents is usually a combination of natural language and semi-structured data in forms of tables, diagrams, symbols, and on. A human inherently reads and understands text regardless of its structure and the way it is represented. Today, computers interact with written (as well as spoken) forms of human language overcoming challenges in natural language processing easily.
According to Statista the NLP market is predicted be almost 14 times larger in 2025 than it was in 2017, increasing from around 3 billion U.S. dollars in 2017 to over 43 billion in 2025. Share on XWhat are the NLP challenges today? In document recognition, NLP service, coupled with the OCR technology, finds applications for data retrieval, information extraction, and text summarization. Today’s technology capabilities allow computers to go over a document from top to bottom and accurately extract everything of value for a company: business-critical insights, information about consumers, and payment data from invoices.
OCR and NLP power state-of-the-art applications that your company can use to complete many document-related tasks not limited to the following:
- Automatically read and recognize ID cards or passports
- Instantly scan bank cards, invoices, tickets, cheques, etc.
- Autofill payment data
- Automatically enter data into various forms or CRM
- Verify customer data gathered from different sources
By opting for data extraction services, business owners can get synthesized information and utilize it for making better decisions and taking informed actions.
Overcoming NLP and OCR Challenges in Pre-Processing of Documents
The output of the OCR process is a text that contains typos, recognition mistakes, non-text symbols, and other inaccuracies. The result may be similar to what is below in the image:

It is a plain text free of specific fonts, diagrams, or elements that make it difficult for machines to read a document line by line.
A tax invoice is more complex since it contains tables, headlines, note boxes, italics, numbers – in sum, several fields in which diverse characters make a text. Such a text has the two-dimensional (2D) structure.
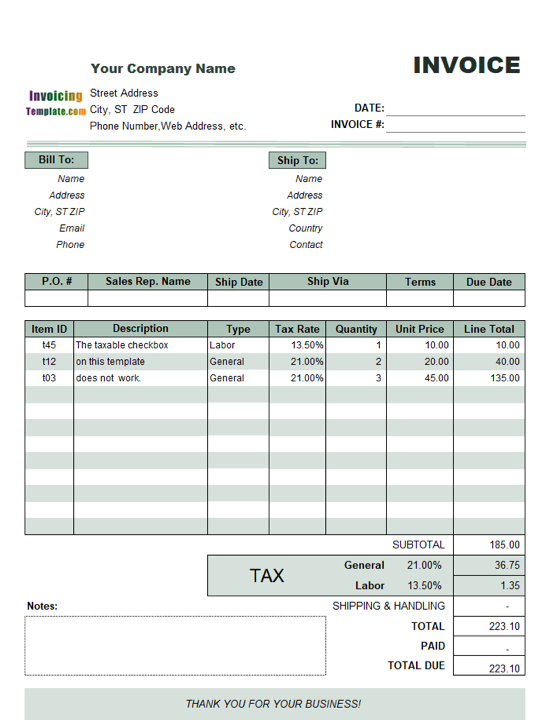
Source: InvoicingTemplates.com
2D texts impose extra data capture difficulties. To overcome natural language processing, engineers need to write appropriate programs and apply relevant machine learning algorithms to read a document considering the size of characters, spacing between lines, location of fields on the page, and other text attributes.
Due to computer vision and machine learning-based algorithms to solve OCR challenges, computers can better understand an invoice layout, automatically analyze, and digitize a document. Also, many OCR engines have the built-in automatic correction of typing mistakes and recognition errors.
For NLP, it doesn’t matter how a recognized text is presented on a page – the quality of recognition is what matters. Tools and methodologies will remain the same, but 2D structure will influence the way of data preparation and processing.
A processing unit in NLP is token – a sequence of characters. The process of chopping each phrase into pieces is called tokenization. A word, number, date, special character, or any meaningful element can be a token.
Processing a word may be harder than it seems. Depending on the context, the same word changes according to the grammar rules of one or another language. To prepare a text as an input for processing or storing, it is needed to conduct text normalization. This task can be solved by reducing each word to its stem or base.
Another natural language processing challenge that machine learning engineers face is what to define as a word. Such languages as Chinese, Japanese, or Arabic require a special approach.
Additional difficulty relates to recognition mistakes. In OCR process, an OCR-ed document may contain many words jammed together or missing spaces between the account number and title or name. All that adds to the complexity of tokenization.
One more possible hurdle to text processing is a significant number of stop words, namely, articles, prepositions, interjections, and so on. With these words removed, a phrase turns into a sequence of cropped words that have meaning but are lack of grammar information.
Document Categorization and Data Capture Using Different Engines
The output of NLP engines enables automatic categorization of documents in predefined classes.
Say your sales department receives a package of documents containing invoices, customs declarations, and insurances. For your business, only invoice data has value. Parsing each document from that package, you run the risk to retrieve wrong information. At this point, you need to use document categorization or classification.
For training a model to classify documents, it is necessary to have thousands of manually label samples that will shape a training dataset. Then, machine learning engineers will define parameters according to which it is possible to associate a document with one or another class. They will use these parameters later to create a classification model.
Different training methods – from classical ones to state-of-the-art approaches based on deep neural nets – can make a good fit. Everything depends on the type of data and business objectives.
Depending on the type of task, a minimum acceptable quality of recognition will vary. At InData Labs, OCR and NLP service company, we proceed from the needs of a client and pick the best-suited tools and approaches for data capture and data extraction services.
So, Tesseract OCR by Google demonstrates outstanding results enhancing and recognizing raw images, categorizing, and storing data in a single database for further uses. It supports more than 100 languages out of the box, and the accuracy of document recognition is high enough for some OCR cases.
ABBYY FineReader gradually takes the leading role in document OCR and NLP. This software works with almost 186 languages, including Thai, Korean, Japanese, and others not so widespread ones. ABBYY provides cross-platform solutions and allows running OCR software on embedded and mobile devices. The pitfall is its high price compared to other OCR software available on the market.
Taking Stock
These days companies strive to keep up with the trends in intelligent process automation. OCR and NLP are the technologies that can help businesses win a host of perks ranging from the elimination of manual data entry to compliance with niche-specific requirements.
Document recognition and text processing are the tasks your company can entrust to tech-savvy machine learning engineers. They will scrutinize your business goals and types of documentation to choose the best tool kits and development strategy and come up with a bright solution to face the challenges of your business.
Optimize Your Business Processes with the Help of Our Data Extraction Services
Have a project in mind but need some help implementing it? Drop us a line at info@indatalabs.com, we’d love to discuss how we can work with you.

