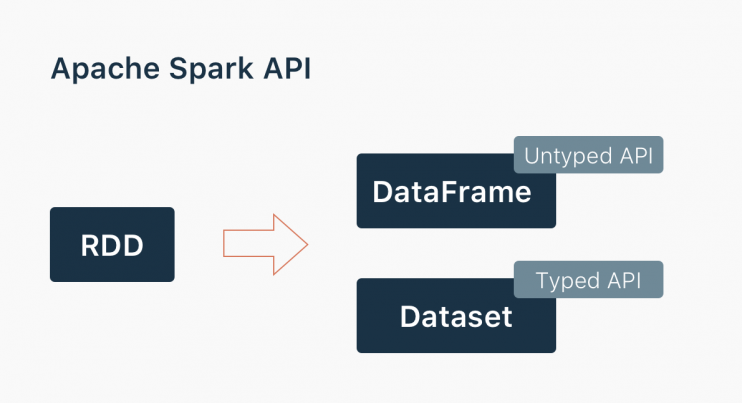
Generally speaking, Spark provides 3 main abstractions to work with it. First, we will provide you with a holistic view of all of them in one place. Second, we will explore each option with examples.
- RDD (Resilient Distributed Dataset). The main approach to work with unstructured data. Pretty similar to a distributed collection that is not always typed.
- Datasets. The main approach to work with semi-structured and structured data. Typed distributed collection, type-safety at a compile time, strong typing, lambda functions.
- DataFrames. It is the Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. Think about it as a table in a relational database.
The more Spark knows about the data initially and RDD to dataframe, the more optimizations are available for you.
- RDD. Raw data lacking predefined structure forces you to do most of the optimizations by yourself. This results in lower performance out of the box and requires more effort to speed up the data processing.
- Datasets. Typed data, possible to apply existing common optimizations, benefits of Spark SQL’s optimized execution engine.
- DataFrames. Share the codebase with the Datasets and have the same basic optimizations. In addition, you have optimized code generation, transparent conversions to column based format and an SQL interface.
Let’s scale up from Spark RDD to DataFrame and Dataset and go back to RDD. All examples will be in Scala. The source code is available on GitHub. We’ll try to leave comments on any tricky syntax for non-scala guys’ convenience.
Prerequisites: In order to work with RDD we need to create a SparkContext object
val conf: SparkConf =
new SparkConf()
.setMaster("local[*]")
.setAppName("AppName")
.set("spark.driver.host", "localhost")
val sc: SparkContext = new SparkContext(conf)RDD
There are 2 common ways to build the RDD:
- Pass your existing collection to SparkContext.parallelize method (you will do it mostly for tests or POC)
scala> val data = Array(1, 2, 3, 4, 5)
data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val rdd = sc.parallelize(data)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26- Read from external sources
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b)Pretty straightforward, right? Things are getting interesting when you want to convert your Spark RDD to DataFrame. It might not be obvious why you want to switch to Spark DataFrame or Dataset. As you might see from the examples below, you will write less code, the code itself will be more expressive and do not forget about the out of the box optimizations available for DataFrames and Datasets. Imagine that you’ve done a set of transformations on unstructured data via RDD and you want to continue with a bunch of aggregations reusing the DataFrames optimizations (Catalyst optimizer and Tungsten’s efficient code generation). What options do you have? Let’s intro to DataFrames first and come back to this question.
DataFrame
DataFrame is based on RDD, it translates SQL code and domain-specific language (DSL) expressions into optimized low-level RDD operations. DataFrames have become one of the most important features in Spark and made Spark SQL the most actively developed Spark component. Since Spark 2.0, DataFrame is implemented as a special case of Dataset.
Most constructions may remind you of SQL as DSL. Naturally, its parent is HiveQL.
DataFrame has two main advantages over RDD:
- Optimized execution plans via Catalyst Optimizer.
- Custom Memory management via Project Tungsten.
Prerequisites: To work with DataFrames we will need SparkSession
val spark: SparkSession =
SparkSession
.builder()
.appName("AppName")
.config("spark.master", "local")
.getOrCreate()First, let’s sum up the main ways of creating the DataFrame:
- From existing RDD using a reflection
In case you have structured or semi-structured data with simple unambiguous data types, you can infer a schema using a reflection.
import spark.implicits._
// for implicit conversions from Spark RDD to Dataframe
val dataFrame = rdd.toDF()
- From existing RDD by programmatically specifying the schema
def dfSchema(columnNames: List[String]): StructType =
StructType(
Seq(
StructField(name = "name", dataType = StringType, nullable = false),
StructField(name = "age", dataType = IntegerType, nullable = false)
)
)
def row(line: List[String]): Row = Row(line(0), line(1).toInt)
val rdd: RDD[String] = ...
val schema = dfSchema(Seq("name", "age"))
val data = rdd.map(_.split(",").to[List]).map(row)
val dataFrame = spark.createDataFrame(data, schema)- Loading data from a structured file (JSON, Parquet, CSV)
val dataFrame = spark.read.json("example.json")
val dataFrame = spark.read.csv("example.csv")
val dataFrame = spark.read.parquet("example.parquet")- External database via JDBC
val dataFrame = spark.read.jdbc(url,"person",prop)- Tables in Hive
If you have semi-structured data, you can create DataFrame from the existing RDD by programmatically specifying the schema.
Let’s take a look at the real-life example and review it step-by-step.
Business problem: “Happy Customers” online support center has 3 managers (Arjun Kumar, Rohit Srivastav, Kabir Vish). Smart internal system randomly picks a manager and assigns it to the new client persistently. Unfortunately, last week’s report showed a decrease in a customer satisfaction rate and you want to start your investigation with an average customer satisfaction per manager.
The dataset in table format:
Manager name, Client Name, Client Gender, Client Age, Response time (in hours), Satisfaction Level (0-1)
The same in “csv”
manager_name, client_name, client_gender, client_age, response_time, statisfaction_level
“Arjun Kumar”,”Rehan Nigam”,”male”,30,4.0,0.5
“Kabir Vish”,”Abhinav Neel”,”male”,28,12.0,0.1
“Arjun Kumar”,”Sam Mehta”,”male”,27,3.0,0.7
“Arjun Kumar”,”Ira Pawan”,”female”,40,2.5,0.6
“Rohit Srivastav”,”Vihaan Sahni”,”male”,38,6.0,0.5
“Kabir Vish”,”Daivik Saxena”,”male”,45,16.0,0.2
“Rohit Srivastav”,”Lera Uddin”,”female”,20,8.0,0.4
“Rohit Srivastav”,”Aaran Puri”,”male”,34,7.5,0.3
“Kabir Vish”,”Rudra Mati”,”male”,50,20.0,0.1
We need to define a schema for the file and create the DataFrame based on it.
“Row” here represents one row of csv data output.
// create DataFrame from RDD (Programmatically Specifying the Schema)
val headerColumns = rdd.first().split(",").to[List]
// extract headers [..] first
def dfSchema(columnNames: List[String]): StructType = {
StructType(
Seq(
StructField(name = "manager_name", dataType = StringType, nullable = false),
StructField(name = "client_name", dataType = StringType, nullable = false),
StructField(name = "client_gender", dataType = StringType, nullable = false),
StructField(name = "client_age", dataType = IntegerType, nullable = false),
StructField(name = "response_time", dataType = DoubleType, nullable = false),
StructField(name = "satisfaction_level", dataType = DoubleType, nullable = fals)
)
)
}
// create a data row
def row(line: List[String]): Row = {
Row(line(0), line(1), line(2), line(3).toInt, line(4).toDouble, line(5).toDouble)
}
// define a schema for the file
val schema = dfSchema(headerColumns)
val data =
rdd
.mapPartitionsWithIndex((index, element) => if (index == 0) it.drop(1) else it) // skip header
.map(_.split(",").to[List])
.map(row)
val dataFrame = spark.createDataFrame(data, schema)Now we can use optimized DataFrame’s aggregations. Take a look at a few lines of code. Pretty simple and, expressive. When you are using DataFrame in the right place you may get space efficiency and speed optimization. Please, refer to this blog post to get more details. Going a little bit ahead we’d like to say that Datasets are optimized for typed engineering tasks, DataFrames are faster for interactive analytics.
So, we can figure out the average customer satisfaction rate using the following code:
data
.groupBy($"manager_name")
.agg(
round(avg($"response_time"), 1).as("time"),
round(avg($"satisfaction_level"), 1).as("satisfaction")
)
.orderBy($"satisfaction")
Now it’s time to complete our investigation and show the output.
Alternatively, you can solve it via Spark SQL which is a separate topic to discuss. The output will be the same. In the middle of the code, we are following Spark requirements to bind DataFrame to a temporary view. The rest looks like regular SQL. When executing SQL queries using Spark SQL, you can reference a DataFrame by its name previously registering DataFrame as a table. When you do so Spark stores the table definition in the table catalog. For Spark without Hive support, a table catalog is implemented as a simple in-memory map, which means that table information lives in the driver’s memory and disappears with the Spark session. In both cases (Spark with or without Hive support), the createOrReplaceTempView method registers a temporary table.
See the example below and try doing it. For more information, you can refer to the Spark SQL language documentation.
val viewName = s"summed"
val sql =
s"""
SELECT manager_name,
ROUND(SUM(response_time) / COUNT(response_time), 1) AS time,
ROUND(SUM(satisfaction_level) / COUNT(satisfaction_level), 1) AS satisfaction
FROM $viewName
GROUP BY manager_name
ORDER BY satisfaction
"""
// before run our SQL query we must create a temporary view
// for our DataFrame, by using following method
summed.createOrReplaceTempView(viewName)
spark.sql(sql)
SQL and DataFrames are different approaches to doing the same. Writing SQL is probably easier and more natural to users who are used to working with relational databases, or distributed databases, such as Hive. We are using SQL mostly for static queries and DataFrame API for dynamic queries for our own convenience. We encourage you to experiment and choose your style.
Dataset
The DataFrame API is radically different from the RDD API because it is an API for building a relational query plan that Spark’s Catalyst optimizer can then execute.
The Dataset API aims to provide the best of both worlds: the familiar object-oriented programming style and compile-time type-safety of the RDD API but with the performance benefits of the Catalyst query optimizer. Datasets also use the same efficient off-heap storage mechanism as the DataFrame API.
The idea behind Dataset “is to provide an API that allows users to easily perform transformations on domain objects, while also providing the performance and robustness advantages of the Spark SQL execution engine”. It represents competition to RDDs as they have overlapping functions.
DataFrame is an alias to Dataset[Row]. As we mentioned before, Datasets are optimized for typed engineering tasks, for which you want types checking and object-oriented programming interface, while DataFrames are faster for interactive analytics and close to SQL style.
About data serializing. The Dataset API has the concept of encoders which translate between JVM representations (objects) and Spark’s internal binary format. Spark has built-in encoders that are very advanced in that they generate byte code to interact with off-heap data and provide on-demand access to individual attributes without having to de-serialize an entire object.
Let’s say we have a case class
case class FeedbackRow(manager_name: String, response_time: Double, satisfaction_level: Double)You can create Dataset:
- By implicit conversion
// create Dataset via implicit conversions
val ds: Dataset[FeedbackRow] = dataFrame.as[FeedbackRow]
val theSameDS = spark.read.parquet("example.parquet").as[FeedbackRow]- By hand
// create Dataset by hand
val ds1: Dataset[FeedbackRow] = dataFrame.map {
row => FeedbackRow(row.getAs[String](0), row.getAs[Double](4), row.getAs[Double](5))
}- From collection
import spark.implicits._
case class Person(name: String, age: Long)
val data = Seq(Person("Bob", 21), Person("Mandy", 22), Person("Julia", 19))
val ds = spark.createDataset(data)
- From RDD
val rdd = sc.textFile("data.txt")
val ds = spark.createDataset(rdd)Here is an example, how to solve our sample business problem using the typed Dataset API.
// custom average aggregator, to round the final value with a scale of 1
class TypedScaledAverage[IN](f: IN => Double) extends TypedAverage[IN](f) {
override def finish(red: (Double, Long)): Double =
(red._1 / red._2 * 10).round / 10d
}
def scaledAvg[IN](f: IN => Double): TypedColumn[IN, Double] =
new TypedScaledAverage(f).toColumn
summed
.groupByKey(x => x.manager_name)
.agg(scaledAvg(_.response_time), scaledAvg(_.satisfaction_level))
.map { case (managerName, time, satisfaction) =>
FeedbackRow(managerName, time, satisfaction)
}.orderBy($"statisfaction_level")Bringing it all together.
Despite each API has its own charm and purpose the conversions between RDDs, DataFrames, Datasets are possible and sometimes natural. We intentionally didn’t cover partitioning, shuffling, data locality and latency topics in this article to keep its size not too large. Please, consider it while working with Spark to get optimal performance. Let’s build the basic checklist when to use RDDs, DataFrames and Datasets. It will help you choose the proper way from the start.
RDD
- your data is unstructured, for example, binary (media) streams or text streams
- you want to control your dataset and use low-level transformations and actions
- your data types cannot be serialized with Encoders (an optimized approach that uses runtime code generation to build custom bytecode for serialization and deserialization)
- you are ok to miss optimizations for DataFrames and Datasets for structured and semi-structured data that are available out of the box
- you don’t care about the schema, columnar format and ready to use functional programming constructs
DataFrame
- your data is structured (RDBMS input) or semi-structured (json, csv)
- you want to get the best performance gained from SQL’s optimized execution engine (Catalyst optimizer and Tungsten’s efficient code generation)
- you need to run hive queries
- you appreciate domain specific language API (.groupBy, .agg, .orderBy)
- you are using R or Python
Dataset
- your data is structured or semi-structured
- you appreciate type-safety at a compile time and a strong-typed API
- you need good performance (mostly greater than RDD), but not the best one (usually lower than DataFrames)
This’s it! Thank you for reading our post. Hopefully, it was useful for you to explore the process of converting Spark RDD to DataFrame and Dataset.
We regularly write about data science, Big Data, and Artificial Intelligence. If you would like to read future posts from our team then simply subscribe to our monthly newsletter. Also feel free to connect on Twitter.
About InData Labs
InData Labs is a data science consulting company, our core services include data strategy consulting, big data analytics services, and artificial intelligence development. Our services allow companies to innovate, experiment with new tools, explore new ways of leveraging data, and continuously optimize existing big data solutions.
Have a project in mind? We’ll make it happen!