
Large language model (LLM) development has rapidly matured from an experimental pursuit into a core capability for enterprises. Far more than chatbots, LLM‑powered systems now ingest proprietary knowledge, automate workflows, and support decision‑making across departments.
This shift has given rise to the specialised profession of the LLM developer, engineers who bridge data pipelines, machine‑learning infrastructure and application logic to deliver production‑grade generative‑AI solutions.
According to Microsoft’s AI blog, LLMs are transformer-based models trained on vast amounts of text that understand context, detect sentiment, and generate human-like responses. Their versatility spans text, code, and multimodal outputs, making them indispensable for modern applications.

This article explores the evolving role of LLM developers, discusses enterprise architecture patterns for deploying LLMs, outlines benefits and risks, and highlights real‑world use cases. The goal is to provide a comprehensive resource for organisations evaluating LLM app development and for technologists aspiring to build careers in this exciting field.
Where helpful, internal links to related topics across the website are included to provide additional context. These resources explore areas such as AI software development, Generative AI company and AI chatbot development, helping readers better understand how modern AI systems are designed and deployed in real-world environments.
What is an LLM developer?
An LLM developer designs, builds and maintains systems that leverage large language models to solve business problems.
The importance of prompt engineering
Prompt engineering sits at the heart of LLM development. Databricks explains that prompt engineering is an emerging field focused on crafting and refining natural‑language instructions to guide AI models. It bridges the gap between human intent and machine understanding by providing context, reducing ambiguity and guiding reasoning.
Effective prompts enable chatbots to ask follow‑up questions, emphasise empathy and handle complex tasks. Prompt engineering sits at the heart of LLM development. Databricks explains prompt engineering as an emerging field focused on crafting and refining natural-language instructions that guide AI models. It bridges the gap between human intent and machine understanding by providing context, reducing ambiguity, and guiding reasoning.
Effective prompts enable chatbots to ask follow-up questions, emphasise empathy, and handle complex tasks. Poor prompts, on the other hand, amplify biases, invite hallucinations and make systems vulnerable to prompt‑injection attacks. LLM developers therefore spend significant time designing prompts and iterating based on user feedback and telemetry.
Core responsibilities
Successful LLM developers operate at the intersection of AI research and production software. Their duties typically include:
- Designing data pipelines. LLMs require high‑quality data. Developers build pipelines that aggregate, cleanse and transform proprietary datasets such as transaction records, operational logs or customer interactions. High‑quality data increases accuracy and reduces model drift over time.
- Implementing RAG and fine‑tuning. Many enterprise applications use retrieval‑augmented generation. NVIDIA notes that RAG links generative models to external knowledge bases, enhancing accuracy and reliability. The technique provides context and citations, reducing hallucinations and building user trust. Developers also fine‑tune base models on domain‑specific data when tasks require deeper customisation.
- Optimising inference performance. LLM deployments must balance latency, throughput and cost. A study by RWS observed that slower models can severely undermine productivity; a 30‑second response time versus 3 seconds disrupts flow and reduces effectiveness. LLM developers therefore integrate techniques such as model quantisation, batching and caching to achieve real‑time responses.
- Monitoring and evaluation. Continuous monitoring tracks accuracy, latency and cost. Developers implement dashboards and automated alerts to detect data drift, identify hallucination patterns and ensure compliance with policies.
- Ensuring security and privacy. Security considerations are also critical when deploying large language models. Coralogix highlights enterprise AI security risks, explaining that organizations must guard against prompt injection attacks, data poisoning, and model-theft threats when integrating LLM systems into production environments. Developers implement input validation, role‑based access control and rigorous audit trails to protect sensitive information.
Skills required
Key skills for LLM developers include:
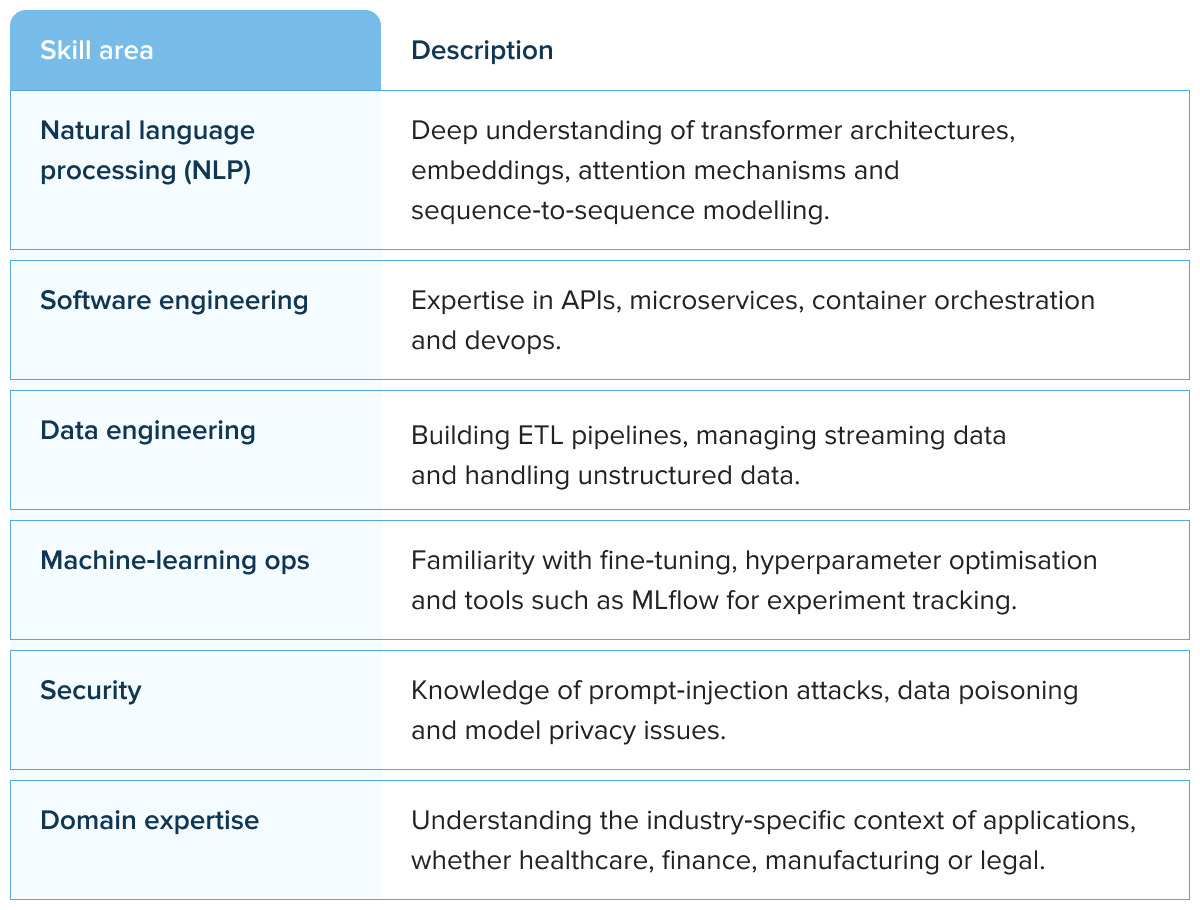
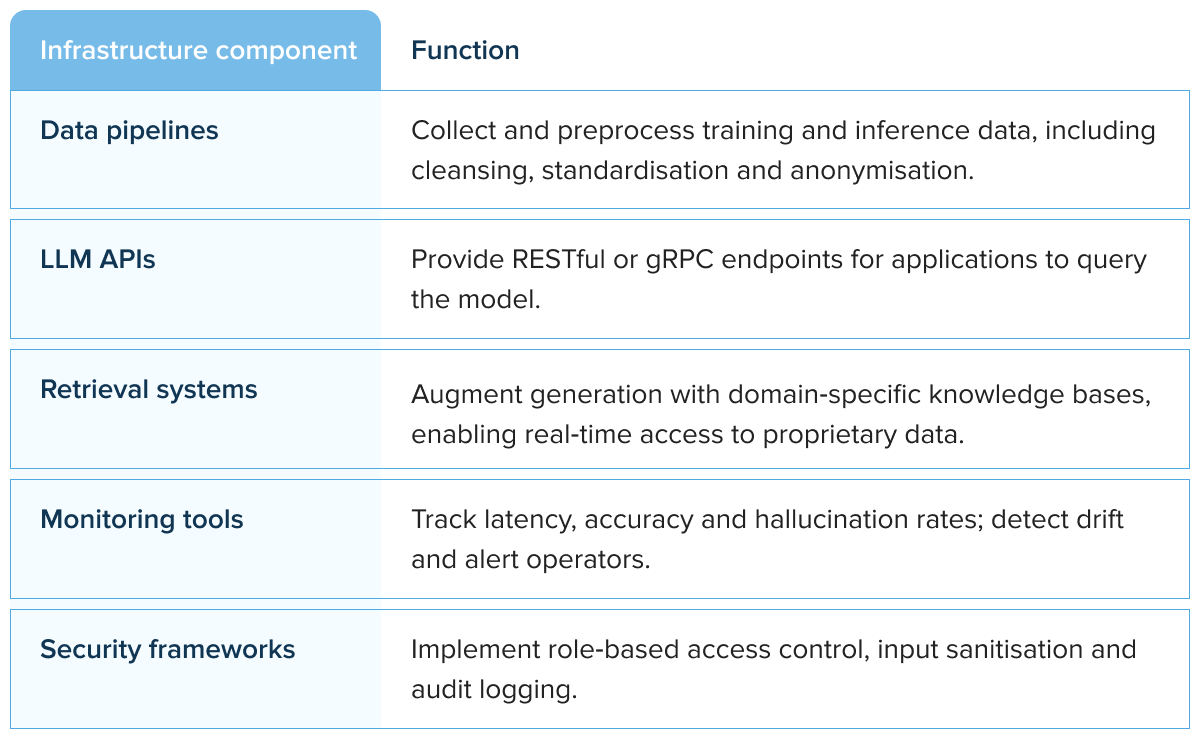
Enterprise architecture for LLM systems
Deploying large language models within an enterprise requires a carefully layered architecture. At a high level, the stack consists of data pipelines, model APIs, retrieval systems, monitoring infrastructure and security frameworks.
The table below summarises typical components and their functions. An LLM developer must orchestrate these components to ensure scalability, reliability and compliance.
RAG vs. fine‑tuning: When to choose each
Enterprises often ask whether to fine‑tune an LLM or use retrieval‑augmented generation. NVIDIA explains that RAG is a general‑purpose fine‑tuning recipe connecting LLMs to external resources. Many enterprise applications use retrieval-augmented generation.
NVIDIA explains retrieval-augmented generation as a method that links generative models to external knowledge bases, improving accuracy and reliability in AI-generated responses. It requires minimal code, is cost‑effective and allows hot‑swapping of data sources. Fine‑tuning, in contrast, modifies model weights using domain data.
While this yields highly specialised models, it is expensive and must be retrained periodically. Generally, organisations choose RAG when they need up‑to‑date information or want to ground answers in a specific knowledge base. Fine‑tuning suits tasks requiring deeper adaptation, such as legal reasoning or domain‑specific summarisation.
Strategic benefits of large language models
Large language models confer significant benefits across industries. Microsoft highlights that LLMs interpret context and nuance, enabling intuitive human‑computer interaction. They generate multimodal outputs, from text to images and speech, streamlining content creation.
Additional benefits include code generation and analysis, task versatility and scalability. These capabilities translate into measurable enterprise value.
Faster access to organisational knowledge
LLMs synthesise information from multiple sources, providing direct answers rather than a list of documents.
For businesses with vast knowledge repositories, research papers, customer emails, operational manuals, LLM‑powered assistants reduce time spent searching and summarising. In regulated industries such as finance or healthcare, retrieval systems ensure answers are grounded in approved data, enhancing compliance.
Automation of document analysis and summarisation
Large models excel at digesting lengthy documents and generating concise summaries. They interpret context, sentiment and nuance, making them ideal for legal contracts, compliance reports or medical literature. With retrieval augmentation, organisations maintain control over the underlying sources, ensuring summarisation is accurate and up‑to‑date.
Improved software development productivity
LLMs support code generation, auto‑completion, debugging and documentation.
Microsoft notes that developers can use LLMs to build applications, auto‑complete code, identify errors, suggest design patterns and create test cases. This accelerates development, reduces repetitive tasks and helps engineers focus on architectural decisions. However, enterprises must choose models carefully, as slower LLMs can undermine productivity.

Source: Unsplash
Natural language interfaces for enterprise systems
LLMs enable conversational interfaces that democratise access to data. Employees can query databases, schedule tasks, or generate reports using natural language.
These capabilities integrate seamlessly with modern AI-powered business platforms and conversational systems such as AI applications for business and AI chatbot enabling organizations to automate workflows and improve access to enterprise knowledge.
Enhanced decision‑making
By synthesising structured and unstructured data, LLMs generate insights that inform strategic decisions. They identify patterns in customer behaviour, predict equipment failures and highlight anomalies in financial transactions. When paired with dashboards and data warehouses, LLMs become a powerful analytical tool in corporate environments.
For readers interested in learning more about the broader business implications of generative AI, additional insights can be found in articles exploring LLM benefits and how organisations can turn these models into game‑changing large language model apps that support customer service, marketing, research and software engineering use cases.
Data infrastructure and governance
Data quality is the foundation of effective LLM deployments. Without robust data governance, even sophisticated models produce unreliable outputs. Enterprises should invest in:
- Centralised data warehouses and lakes. Consolidate structured and unstructured data into unified repositories with version control. Versioned datasets enable reproducibility and compliance audits.
- Streaming and batch pipelines. Use tools that support both real‑time and historical data processing to feed LLMs with up‑to‑date information.
- Data validation and anomaly detection. Implement rules to catch missing values, outliers or schema changes before they reach models. Validating input prevents data poisoning attacks.
- Dataset documentation. Record metadata such as sources, collection methods and licenses. This enhances transparency and supports ethical AI practices.
Security and privacy considerations
Coralogix emphasises that enterprises face security risks such as prompt‑injection attacks, training‑data poisoning and model theft. Attackers may embed malicious instructions into prompts, manipulate training data or exfiltrate proprietary models. Organisations should implement:
1. Input sanitisation. Remove harmful instructions or code from user prompts before forwarding them to the model.
2. Role‑based access control (RBAC). Restrict model usage based on job function. RBAC helps prevent unauthorised data exposure.
3. Monitoring and anomaly detection. Detect unusual patterns in queries or outputs that could indicate prompt‑injection or model exploitation.
4. Secure model hosting. Protect underlying weights and architecture to prevent extraction and reverse engineering.
5. Governance policies. Define acceptable use, explainability requirements and procedures for handling sensitive data.
Scaling LLM systems
Scaling LLMs introduces challenges around cost, latency, integration and multilingual performance. RWS’s enterprise AI study shows that each 100 ms of latency can reduce sales by 1%. When generative‑AI models take seconds rather than milliseconds to respond, users experience context‑switching overhead that degrades productivity.
Research from RWS indicates that slow model responses can significantly undermine productivity. When response times increase from a few seconds to half a minute, user workflows are interrupted and overall efficiency declines. Moreover, many LLMs underperform in less‑represented languages, undermining global scalability. To scale effectively:
- Choose the right model. Evaluate models not only on benchmark accuracy but on latency, token efficiency and domain‑specific performance.
- Implement caching and batching. Reuse results for identical queries and process requests in batches to improve throughput.
- Use distributed inference. Deploy models across multiple GPUs or use serverless inference platforms to handle peak loads.
- Adopt hybrid architectures. Combine on‑premises infrastructure for sensitive data with cloud‑based compute for scalable inference.
- Test multilingual performance. Conduct pilot evaluations in all target languages to avoid performance surprises.
Real‑world use cases
Large language models power a wide range of enterprise applications. Some notable examples include:
Knowledge assistants and research tools
LLM‑powered knowledge assistants allow employees to query internal documentation using natural language.
In complex industries such as law, pharmaceuticals and aviation, these assistants reduce the time required to find relevant information by summarising manuals, contracts or technical papers. Retrieval‑augmented generation ensures responses are grounded in approved sources, increasing reliability.
Source: Unsplash
Customer‑support automation
Conversational AI chatbots built on LLMs can handle frequently asked questions, troubleshoot problems and route complex issues to human agents. They integrate easily with existing AI chatbot platforms and can be deployed across web, mobile and voice channels. Prompt engineering ensures they ask clarifying questions and respond with empathy.
Document analysis and summarisation
In finance and legal services, LLMs analyse lengthy documents to extract clauses, summarise terms and flag anomalies. By automating these tasks, firms reduce the manual workload and free experts to focus on strategic analysis.
AI‑assisted software development
Code‑generation models assist developers with scaffolding projects, writing unit tests and diagnosing errors. They accelerate prototyping and reduce time spent on repetitive coding tasks. Companies building internal tools can integrate these capabilities into development environments, increasing productivity and consistency.
Research automation
LLMs summarise scientific papers, generate literature reviews and identify key trends. They enable researchers to digest large volumes of publications quickly, guiding strategic decisions and innovation.

Source: Unsplash
For readers interested in the broader business implications of generative AI, additional insights can be found in articles exploring large language model use cases and how organizations are building advanced large language model apps that support customer service, marketing, research, and software engineering workflows.
How to build a robust LLM team
The complexity of enterprise LLM projects requires multidisciplinary collaboration. Successful initiatives usually include:
- LLM developers who design architectures, implement inference pipelines and optimise prompts.
- Data scientists to curate datasets, perform fine‑tuning and evaluate model performance.
- Software architects to integrate LLM services into existing systems and ensure scalability.
- Security specialists to design guardrails against prompt injection, data leakage and model theft.
- Product managers to align AI capabilities with business goals and user needs.
LLM developer vs. traditional machine‑learning engineer
One of the questions readers often ask is how an LLM developer differs from a more general machine‑learning engineer. The distinction lies not in the programming languages or frameworks but in their scope and focus.
Traditional ML engineers excel at building and tuning models such as convolutional neural networks or recurrent neural networks, often centred on structured data or specific predictive tasks. They design algorithms, perform hyperparameter optimisation and implement training loops.
LLM developers, by contrast, work with transformer architectures and large context windows. They specialise in prompt engineering, reinforcement learning from human feedback (RLHF) and retrieval‑augmented generation.
Rather than building models from scratch, they integrate pre‑trained models via LLM APIs, connect them to vector databases and orchestrate them within complex enterprise systems.
Their work overlaps with backend development, devops and natural‑language processing. For organisations navigating the transition from generic machine learning to generative AI, partnering with an AI consulting team can help clarify which skills are required and how to structure cross‑functional teams.
Must‑have tools in a modern LLM tech stack
Building robust LLM applications requires a rich toolchain beyond the core model. At a minimum, developers need:
- Deep‑learning frameworks. PyTorch and TensorFlow remain the de facto choices for custom model training and fine‑tuning. Tools like Hugging Face Transformers provide access to state‑of‑the‑art models and simplify tokenisation, attention masking and beam search.
- Prompt‑engineering platforms. Libraries such as LangChain, LlamaIndex and LLM agent development frameworks help compose prompt templates, manage chains of thought and build agentic workflows that call external tools and APIs. These platforms simplify context‑window management and reasoning across multiple steps.
- Vector databases and retrieval systems. Pinecone, Milvus and Weaviate store text embeddings and enable fast similarity search for retrieval‑augmented generation. When coupled with NLP tools like spaCy or NLTK, they form the backbone of RAG pipelines.
- Monitoring and observability tools. Open‑source systems such as Prometheus, Grafana and MLflow collect metrics on token usage, latency and hallucination rates. They support traceability and help measure model performance across parameters like accuracy, precision and recall.
- Security frameworks. Tools that scan prompts for malicious patterns, enforce role‑based access control and perform output sanitisation are essential for enterprise deployments. Modern LLM software development requires integrated threat‑detection services to guard against injection attacks.
An effective tech stack also involves deployment options—from containerised microservices to serverless functions.
When building full‑stack LLM development environments, developers should evaluate hybrid architectures that combine on‑premises clusters with cloud‑based inference services. Our large language model development team can help design such environments and recommend the right mix of tools.
Context windows, AI agents and the future of reasoning
The size of an LLM’s context window determines how much text it can consider in one prompt. Larger windows enable richer reasoning, multi‑document summarisation and more coherent conversations.
However, they also increase computational cost and latency. Prompt engineers must therefore decide how to structure interactions—splitting long documents into chunks or using summarisation to fit context limits. Future models will likely incorporate hierarchical memory and retrieval mechanisms, allowing dynamic expansion of context without quadratic compute costs.
Another innovation gaining traction is the use of AI agents, systems that chain together multiple LLM prompts, external tools and reasoning steps to accomplish complex tasks. For example, an agent might receive a natural‑language instruction to “draft a market analysis,” retrieve relevant reports via a RAG system, summarise them, generate a narrative and finally create a slide deck.
These agents rely on orchestration frameworks (e.g., LangChain Agents) and require careful control of context windows to maintain coherence. They also raise questions about evaluation: how do we measure the performance of an agentic workflow? Metrics may include task completion rate, correctness of intermediate steps and user satisfaction.
Seven types of AI and where LLMs fit
To contextualise LLMs within the broader landscape of artificial intelligence, it helps to consider the “seven types of AI” framework often used to describe progressive levels of capability. These categories range from reactive machines that respond to immediate input, to limited‑memory systems like self‑driving cars that use short‑term historical data.
At higher levels are theory‑of‑mind and self‑aware AI, currently hypothetical constructs in science fiction. The more practical distinctions are between narrow AI, which performs a single task extremely well (like a recommendation engine), general AI, which can perform any intellectual task a human can, and superintelligent AI, which exceeds human abilities.
LLMs fall into the narrow AI category because they excel at natural language processing tasks but lack true understanding or agency. Their transformer architecture and training via RLHF enable them to generate coherent language and synthesise knowledge, but they cannot autonomously set goals or exhibit self‑awareness.
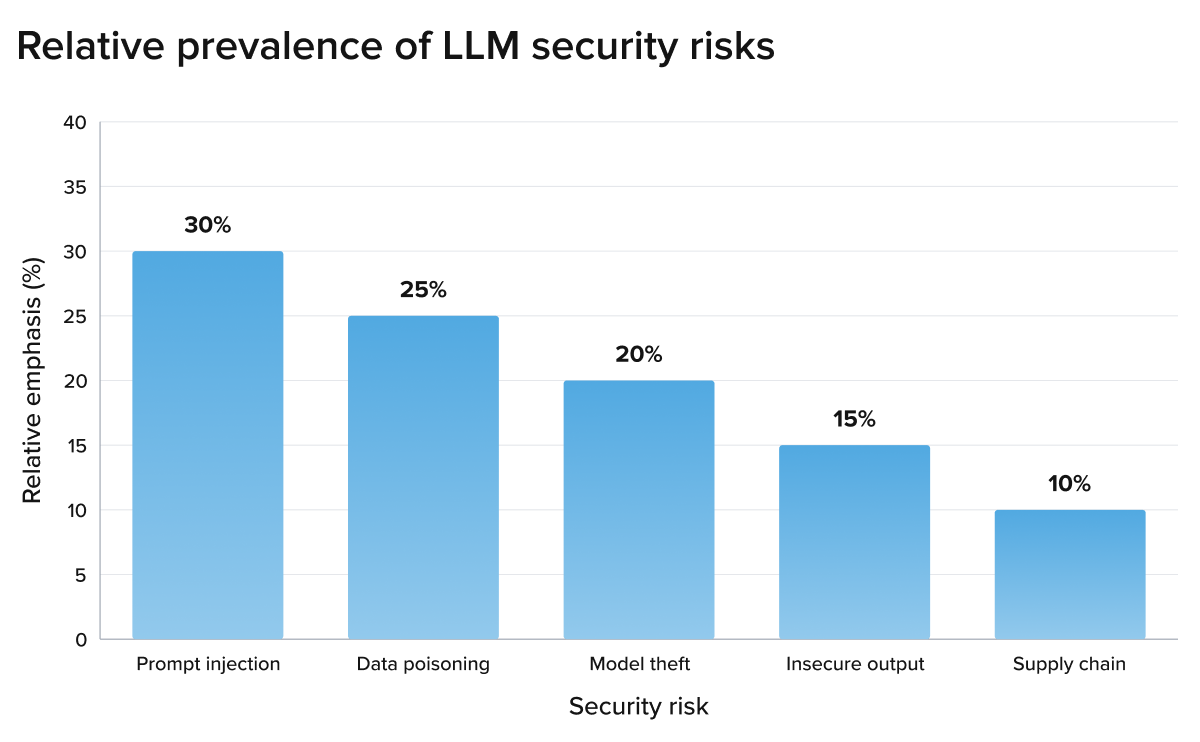
Graph: Distribution of security risks in enterprise LLM deployments
To visualise the importance of security, the following chart illustrates the relative prevalence of the main LLM security risks identified by Coralogix, based on the emphasis given to each vulnerability in the article.
Building sustainable AI capabilities
To realise long‑term value from large language models, organisations must treat AI not as a one‑off experiment but as a core capability. Key practices include:
- Continuous improvement. Retrain models regularly using fresh data, monitor performance metrics and refine prompts. Experiment tracking tools (e.g. MLflow) help teams compare versions and maintain reproducibility.
- MLOps practices. Adopt continuous integration and deployment for ML models, use automated pipelines for retraining and ensure proper versioning of datasets and code. This reduces technical debt and supports rapid innovation.
- Ethical governance. Establish cross‑functional committees to oversee fairness, transparency and compliance. Document the rationale behind prompt designs and monitor models for biases and harms.
- Talent development. Invest in training programmes to upskill existing engineers in prompt engineering, RAG and security. Hiring experienced LLM engineers or partnering with a Generative AI company can accelerate development. For organisations planning new products, our guide to LLM product development explains how to structure cross‑functional teams and deliver customer‑ready solutions.
Conclusion
The rise of LLM developers reflects a broader shift in enterprise technology, from isolated AI experiments to production-grade systems embedded in daily operations.
As organizations scale generative AI across knowledge management, automation, software development, and decision support, the value of LLM developers lies not only in building models, but in connecting data, governance, security, and application logic into reliable business infrastructure. Their role will continue to grow as enterprises seek AI systems that are accurate, secure, and operationally effective.
FAQ
-
Large language models originate from research labs and technology companies such as OpenAI, Google, Meta and Microsoft. Enterprise‑ready LLM applications are often delivered by specialised vendors or AI services providers that offer custom integration, fine‑tuning and support.
-
There is no universal best model. The choice depends on use case, language requirements, latency tolerance and cost. RWS recommends evaluating candidate models across real‑world tasks, including multilingual performance and scaling requirements.
-
An LLM in the context of software development refers to a transformer‑based model trained on large text corpora that can generate and interpret code, documentation and user requirements. LLM developers integrate these models into development tools to accelerate coding and debugging.
-
LLMs can generate and analyse code, but they do not replace human programmers. They act as assistants, automating routine tasks and suggesting improvements while human developers maintain oversight and make architectural decisions.
-
Developers employ retrieval‑augmented generation to ground responses in authoritative sources, design precise prompts, and monitor outputs for anomalies. RAG systems can cite sources, improving transparency and reducing hallucination risk.
-
Use RAG when the task requires up‑to‑date information or access to proprietary data without expensive retraining. Fine‑tuning is appropriate for specialised tasks where the base model’s knowledge must be deeply adapted to the domain.
-
They avoid sending sensitive data to external endpoints whenever possible, anonymise user inputs and outputs, and apply encryption and access controls. Enterprises may choose on‑premises deployments or privacy‑preserving techniques such as federated learning and differential privacy.
-
Key challenges include latency, cost, multilingual performance and security. Enterprises must evaluate models against realistic workloads, implement caching and batching, and ensure robust access controls.


