
Recently, head pose estimation has become a popular area of research. Data scientists have spent over 20 years researching the most effective approaches to it, уеt haven’t settled for one. The technology is needed for facial recognition, eye gaze estimation and emotion recognition. For instance, it can be used for safety monitoring on the road, where we need to understand whether a driver pays attention to the road or not. Finally, It could also be used in computer graphics and VR applications to render a specific scene correctly.
Head Pose Estimation Using Landmarks
Before jumping straight into the discussion of the approaches, let’s understand what Head Pose Estimation is about.
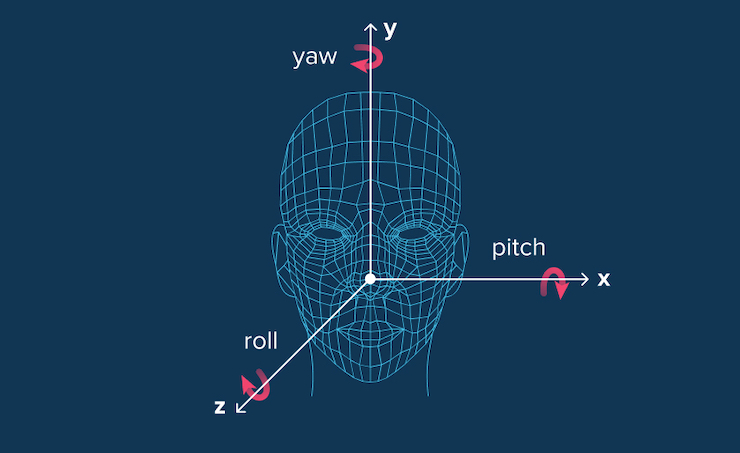
The main objective of this task is to find the relative orientation (and position) of the human’s head with respect to the camera. In particular, in the head pose estimation task, it is common to predict relative orientation with Euler angles – yaw, pitch and roll. They define the object’s rotation in a 3D environment.
So, the head pose estimates can provide information on which direction the human head is facing. Despite the head pose estimation task may seem to be easily solved, achieving acceptable quality on it has become possible only with recent advances in Deep Learning.
Challenging conditions like extreme pose, bad lighting, occlusions and other faces in the frame make it difficult for data scientists to detect and estimate head poses. AI pose detection technology is the technology that makes it easier to do.
Gentle Guide to Head Pose Estimation
Recent Deep Learning methods have revolutionized the field of Computer Vision, reaching near-human quality on a wide range of tasks such as facial recognition and landmarks estimation, object detection and classification. The Head Pose Estimation problem is not an exception and several solutions to this problem have been recently proposed. Now we will describe two possible ways to approach this task. The first one is based on the estimation of facial landmarks, whereas the second one proposes an end-to-end system that directly produces the required estimates.
2D and 3D Head Pose Estimation with Deep Learning
Simply put, head pose estimation means detecting the position of a human head in the image. Particularly, it means detecting the head’s Euler angles – yaw, pitch and roll. They define the object’s rotation in a 3D environment. If you make the right prediction about these three, you’ll find out which direction the human head will be facing.
What do you need for head estimation in real time?
1) 2D coordinates of facial landmarks
You need 2D locations of a few facial landmarks on the image. That might be eyes, eyebrows, a nose tip, lips, chin, etc.
2) 3D coordinates of facial landmarks
You might need a 3D pose estimation model of the human face.
3) Camera parameters
You need to calibrate your camera (camera focal length, image optical center, radial distortion parameters should be considered).
A Two-Step Approach to Head Pose Estimation
This approach assumes that the camera is calibrated, i.e. intrinsic camera parameters (camera focal length, image optical center, radial distortion parameters) are known. If they are unknown, the optical center can be approximated by the center of the image, the focal length – by the width of the image in pixels, radial distortion can be assumed to be zero.
First, as a preprocessing step, we need to apply a face detection algorithm to an image to detect regions of interest, human faces, presented in the image. One could use any DL-based method for face detection, including Faster R-CNN or SSD (available in OpenCV). This step is required to find regions that are cropped from the image and then are processed further in the next steps of the algorithm.
A possible result of the face detection algorithm:

Source: Unspalsh
Then the described approach can be divided into two stages:
Facial Landmarks Detection
In this step, we need to establish the correspondence between 2D facial landmarks in the image and their 3D positions. Under facial landmarks we mean some facial keypoints, e.g. eyes, eyebrows, a nose tip, lips, chin, etc. Obtaining this alignment is necessary for the next step of the algorithm, where the alignment will be used for the optimization procedure.
There are two steps in obtaining this correspondence:
a) Using any 2D landmark tracker, e.g. FAN, Dlib, find facial landmarks on an image. The result of this algorithm would be a set of (x, y)-coordinates of the facial landmark in the image;
b) To find correspondences in 3D space, a 3D human face model is usually fitted. In practice, it is common to fit a simple human mean face model, although other more sophisticated models such as 3DDFA could be also used.
Optimization for Head Pose Parameters
The final stage of the algorithm is the optimization for the head pose parameters.
It is known that the motion of a rigid 3D object w.r.t. to the camera can be fully described with rotation and translation vectors. So, to find head pose parameters we need to find rotation matrix R and translation vector t that define the correspondence between world and camera coordinate systems. The problem of finding R and t given intrinsic camera parameters and a set of 3D points on the object with their 2D projections in the image is usually referred to as Perspective-n-Point problem. We could solve this problem using OpenCV functions solvePnP or solvePnPRansac. The result of this optimization procedure gives us the required head pose parameters. For a more detailed explanation of optimization procedure please refer to this article.
The performance of this approach is very sensitive to errors in facial landmark predictions and depends heavily on the head model chosen as well as the subset of points used for the alignment of the head model or the final optimization method. But can we circumvent these issues and construct a more robust approach? The answer is yes, and we describe it in the next section.
End-to-End Approach to Estimate Head Poses
To avoid the problems of the previous approach, the authors of Hopenet proposed to directly predict the yaw, pitch and roll from the RGB image of a human’s head using a deep neural network. Using this strategy, they succeeded in getting a more robust, faster and accurate approach to head pose detection.
Now let’s look in detail how the proposed method works.
a) Network architecture
The network architecture is provided on the following image:
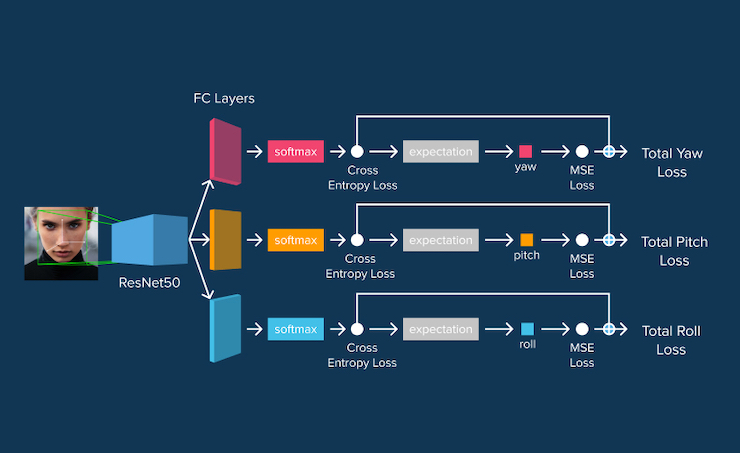
The authors propose to use a three-branch neural network structure, where each branch is responsible for each of the Euler angles. All branches share a backbone network that can be of arbitrary structure, e.g. ResNet50, AlexNet, VGG. This backbone network is augmented with a branch-specific fully-connected layer that predicts a specific angle.
Instead of directly predicting values for the angles, the authors proposed to divide the angle range (360 degrees) into n bins. In this case, each branch of the network outputs a vector of size n. This output is fed into the softmax layer for normalization and the resulting vector essentially provides the probability distribution for a specific angle to lie in a particular bin. Finally, the fine-grained angle predictions are obtained by computing the expectation of each output angle for the binned output.
The main motivation for using a predicting probability distribution for bins is to use cross-entropy loss function, making the network robustly locate the vicinity of the pose.
b) Loss function:
The model is trained using three losses, where each loss is for a specific branch. Due to the introduction of binned classification, each loss is a linear combination of mean squared error loss of the fine-grained angle predictions and cross-entropy loss that uses predicted probability distribution vectors.
To Sum Up
Head pose estimation with deep learning and Computer Vision is vital for vision-based application development. Face recognition apps, video surveillance systems, AI fitness and therapy apps – all of them more or less utilize head pose estimation algorithms.
Want to know about the current state of Human Pose Estimation technology, how it works, in what sectors it can be applied and the adoption challenges? Download report for free here.

