
Facebook has been around since September 2006. A person must be at least 13 years old in order to register on the social network. The users who were in their teens in 2006 are graduating now. Those who were studying – own businesses and take their children to school. Time is passing by and our digital activities are changing with age, while giving more opportunities for age prediction.

As we are getting older, our speech is changing and our vocabulary is enriching. That is one of the key fields of studies in psychology. But did you ever think of exploring such an issue by means of “Big Data” of our own language. Using predictive mathematical model based on frequency statistics we will be able to show you how age prediction works.
Let’s Start with Simple Explanation of Age Prediction and then Move to Formulas and Algorithms.
Explanation of Age Prediction
Imagine, we have a set of Facebook users with lots of statuses. Our every move is recorded: we share our impressions, actions, plans, or just simply say “Hi” to the world sometimes. As every user has a certain date of birth, similarly each status has its publication date. It is possible to build frequencies of words and expressions for every user. Building such statistics across the whole set of users available, we can predict age of new users by answering the question: “Which pattern form the data set does this user’s status match?”. The whole process of age prediction can be described in one scheme (Figure 1).

Figure 1
Now we are ready to introduce the mathematical model describing every step of the scheme.
We have a set of M users, user1, user2, …, user M. Every user’s date of birth is available. And every user has a set of Nm statuses, m={1,2,…,M}. Every status is divided into “text” and “date published”.
Having our users’ statuses, dates of birth and publications, we can divide statuses into same-age groups for the whole user set, concatenate them all in order to produce the result in a form of texts specific for each year. Then we divide them into tokens and perform feature selection (neither tokenizer nor feature selection process are specified here – find the best ones depending on situation). Now we have age-specific vocabulary sets.
In order to build our predictive model we will need to do some reorganization (sorting, grouping, etc.) inside our “Sets”. Then we can make predictions.
We get another user with many Facebook statuses available. The task is to guess his age.
Formulas and Algorithms
As we don’t have any information about the user’s date of birth available, we’ll assume that 1 year is not really a big inaccuracy. Then we divide new user’s statuses year by year. Perform the same operations and compose “each year text” from statuses and get age-specific vocabulary sets for this particular user. When the “Sets” are ready, we use a pattern matching to find similarity between the built sequence of sets and the sequences that are in our predictive model.
Mathematical interpretation is the following:
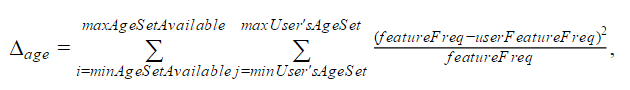
![]()
We all have behavioural patterns that remain unexplored by psychologists but can be easily recognized by machine learning algorithms. Having access to big data sets we can get use of it not only predicting age, but also contributing to psychological studies.
By Hanna Rudakouskaya for InData Labs.
Using machine learning, AI and Big Data technologies InData Labs helps tech startups and enterprises explore new ways of leveraging data, implement highly complex and innovative projects, and build breakthrough AI products. Our core services include Data Strategy Consulting, Big Data Engineering, Data Science Consulting.

