OCR to Recognize and Extract Data from Driver’s Licenses, ID Books, and Smart Cards
Improved recognition accuracy up to 90%.

Improved recognition accuracy up to 90%.
-
ChallengeIdentifying and deriving sensitive data from image scans and facilitating document-based processes
-
SolutionOCR-based solution to capture and retrieve data from document scans automatically
-
Technologies and toolsPython PyTorch Tesseract Opencv
Client
The client is a South African content management solution provider that works with the key players in the banking industry of the country. The client’s main objective is to assist companies in capturing and managing data assets in order to improve operational efficiency. To accomplish this, they integrate different automation toolkits.
This case study will highlight our expertise in computer vision and the importance of OCR when dealing with document scans.
Challenge: capture and derive data from document scans and facilitate document workflow
The client deals with large volumes of data on a regular basis. Manual data search and its recognition from ID books, smart cards, driver’s licenses or any other documents are time-consuming and tedious. That’s why the client was looking for automated data capture and extraction solution. They needed an expert opinion on integrating OCR into their ERP system to handle critical business functions. But the primary objective was to leverage data from document scans and reduce its manual processing and entry because it was taking much time.
The major challenge for our team was to capture and retrieve data from photo scans that often vary in orientations, positions, colours, backgrounds, and lighting conditions. We delivered a service that helps recognize objects in the image scans and determine what data needs to be derived.
Solution: OCR-based solution to automate data capture and extraction from document scans
Having broad experience in OCR implementation, the InData Labs team provided the client with a custom-made solution that helps automate data-based business processes in the client’s workplace and improve the overall work performance.
Our team investigated the feasibility of extracting and recognizing text fields such as name, surname, ID, valid from/to from driver’s licenses from DMV databases, business cards, ID books, and smart cards using OCR. When it comes to leveraging data, these types of documents are uneasy to deal with. In this case, facial recognition comes to aid and helps derive data from damaged driver’s licenses or blurred ID books.
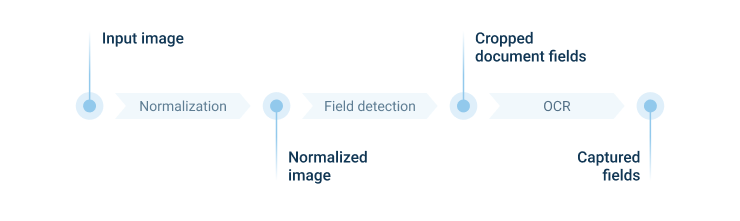
The next step was finding out how to use facial recognition to identify an individuals face in their driver’s license photo or any other document scan. We started developing image pre-processing functionality that significantly improved the efficiency of a commercial built-in OCR engine by automated cropping, rotation and deskewing. We also advanced the existing document classifier to distinguish 3 types of documents: a smart card, ID book, and a driver’s license. We split this process into two phases: image normalization and field recognition.
1. Image normalization
The main challenge for the OCR engines is to recognize rotated, skewed, darkened and blurred scans as well as photo scans with a complex background that usually leads to misunderstanding and errors. To mitigate that, we trained a model to capture a document, crop it, and deskew an image. This phase significantly improved default pipeline recognition. As a result, we got a document without any background positioned correctly.
2. Field recognition
The next task was to capture and identify the required fields in the normalized image. To complete this, our data scientists trained another ML model that predicts where exactly the particular field is located. Having the precise location of the required fields they could crop them from the normalized image and identify them independently. That gave our team more freedom in preprocessing and optimizing the performance of the OCR engine.
To recognize the required fields we applied Tesseract OCR or Captiva built-in OCR engines.
Take a closer look at the OCR use case diagram:
Result: OCR data capture and extraction solution to reduce manual effort
Having extensive technical expertise in developing image recognition solutions, our engineers have delivered a robust solution that automatically captures and derives sensitive data from driver’s licenses, ID books, and smart cards and increases the overall operational efficiency in the client’s workplace.
Our solution enables the processing of a document scan in 2 seconds. 4 document scans can be processed simultaneously. The recognition accuracy is about 85-90%.
Cooperation with us has empowered the client in the following aspects:
- Automated text and image recognition
- Easy and smart data extraction from scanned papers
- Overall speedup when processing scanned text and images
- OCR integration into the client’s ERP system
- Reducing the manual effort in the client’s workplace

