As one of the most hyped fields of AI, computer vision has applications in different areas of business and everyday life. Cision reports that computer vision is set for more growth in popularity. The AI in computer vision market is predicted to reach $25,32 billion by 2023. Share on X
Computer vision technology has revolutionized retail, healthcare, sports, automotive, and fintech industries. The benefits it’s provided them with are immense. Improved customer shopping experience, increased sales, automated routine processes, effective diagnostics, fraud prevention etc. – all of that wouldn’t have been possible without computer vision.
No doubt, that technology isn’t flawless, but it’s proved its effectiveness in image detection and recognition. Some experts claim that it’s got great potential and will be gaining momentum in 2021. Others argue whether it is possible or not to teach machines to perceive the world like us. Let’s shed some light on this controversial point.
What is Computer Vision?
Computer vision is a part of AI that enables computers to see and understand digital videos or images. And visual systems surround us everywhere: smartphone cameras, surveillance systems, sensors, self-driving vehicles, medical images, and so on.
This section of visual machine learning includes several classical tasks, such as image classification, image segmentation, object detection and tracking, and more. In our previous blog article, we explained how deep learning in image recognition works. This time we seek to draw your attention to the concept of visual search.
What is Visual Search Technology?
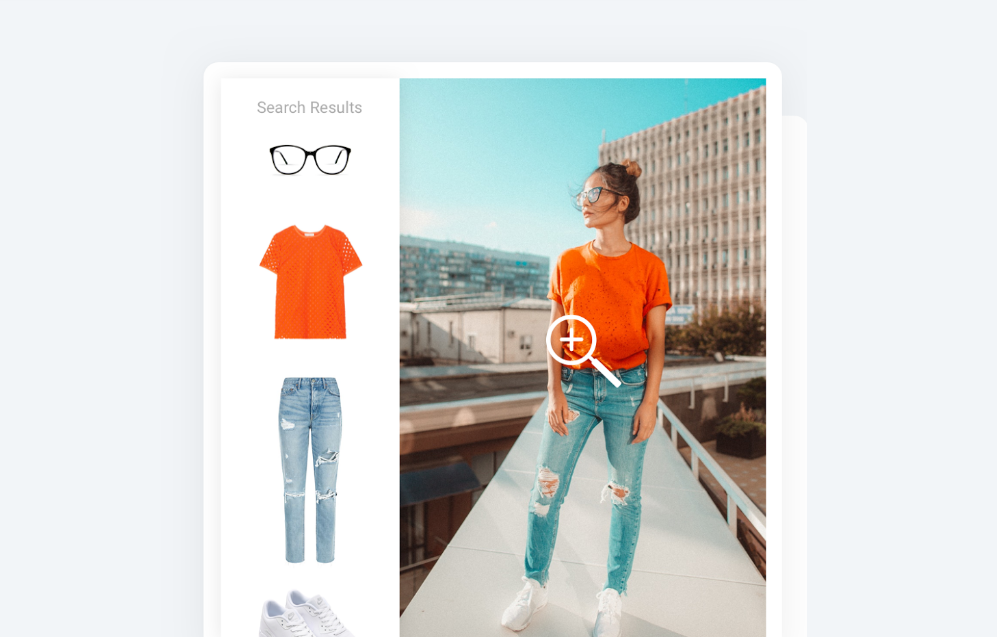
Visual search is the capability of computers to scan what is going around, search, and recognize a target object on the background and filter out irrelevant targets. How does image search work? A clear example is the advanced model image search by Google and Kiddle, a visual search engine for kids that helps filter content, or a visual search tool in the mobile app by ASOS.
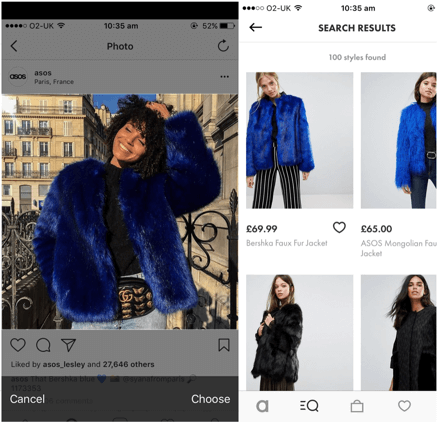
Source: Theverge.com

Source: Safety.com
When customers see a celebrity wearing a lovely dress, they don’t need to painfully pick words for a search engine capabilities. Uploading a single photo or a screenshot is enough to find similar items in online stores. You can try a visual search engine demo by InData Labs to learn the perks. But first, let’s find out what hides under the hood of a user-friendly search option powered by machine learning.
Top Visual Search Applications
Since the technology has been gaining popularity, there are a lot of industries it can be applied to, and visual search applications. Here are the key ones:
Easy and Smooth Search in E-commerce Stores
With the abundance of online stores, E-commerce businessmen are looking for ways to outstand their competitors and achieve better results. One of the options to do that is visual search. The technology simplifies the search by suggesting the user upload an image and offering them similar results.

Source: Unsplash
It’s fast, efficient and customer-friendly. More and more stores are adopting the tech to replace the traditional type-and-search method to provide better shopping experiences and generate more business benefits.
Piracy Control
The modern technology enables piracy content identification in real time, thus helping media owners protect their content rights. It seems to be a great solution for piracy content detection and its distribution prevention.
Brand similarity search helps brands monitor and identify counterfeits and fight it. Visual search-powered solutions aim to detect fake products and prevent shoppers from buying them.
Influencer Search
Using the technology, it’s easy to find relevant bloggers to cooperate with. Gender, sex, age, interests, these can be identified by the modern tech. Whenever you need an influencer, you can get a list of people to collaborate with in just a few seconds, and shortlist the ones that suit you most.
Basic Similarity Search Draws On Powerful Data
Big data reigns in the field of computer vision. Even the most powerful algorithms will fail to make an AI project a success without data that have predictive power. Engineers use massive datasets and apply task-specific methods to teach machines to see, compare, and pick relevant results from large pools of options.
Labeled Faces in the Wild
A typical application of visual search functionalities is in similarity search, like for face recognition apps. As one of the most popular uses of technology, face recognition is the moving force in the evolution of visual search engines.
We will take a face dataset to demonstrate how visual search works. Labeled Faces in the Wild (LFW) is a dataset designed to evaluate face recognition models.
The dataset contains 13,233 images of 5,749 people, where 1,680 of the people featured have two or more photos. All photos in the dataset are pre-organized into pairs. A photo pair has either the same person or two different people as given below:
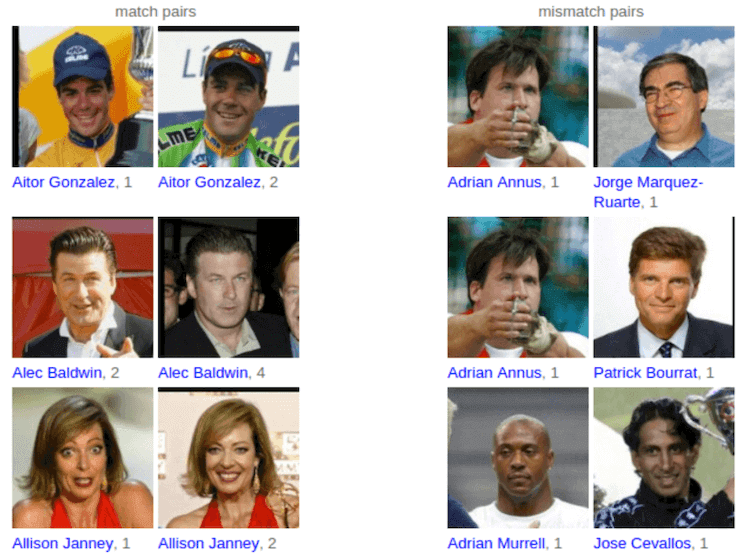
The LFW dataset serves as a baseline to verify the quality of a model. To do this, engineers need certain parameters. For instance, the threshold value that indicates the level of similarity between two photos on a scale from 0 to 2, where 0 means the same person, and 2 means different people.
All the photo pairs in the dataset are split into 10 parts. 9 out of 10 are used to elicit the threshold, and one part is used for model testing. The result is a numerical value – let’s say 0,5 on the scale – that the model assigns to an image. Then engineers do it all again but take different 9 parts and leave a different part for testing. The process is repeated until retrieving 10 values. The average is the numerical value describing the accuracy of the model.
Such a method can be applied not only to searching and comparing faces. Be it a dataset containing domestic appliances, machinery parts, or medical scans – all will do fine.
Simple Approaches in Visual Search Are Ineffective
Since the revolution in artificial neural networks, some methods used to solve business challenges have become less effective and less popular. Latest algorithms work based on black-box principles, which significantly impacts results.
L2 Distance Between Matrices
This method relies on image matrices. A matrix is an image converted into a machine-readable form where each pixel is described in the numerical format depending on the color:

Source: Blog.kleinproject.org
With two images matrices, an algorithm can calculate the mathematical distance between images, which will allow measuring the similarity of these images. Let’s turn to the LFW-based results below:

The close to the original photo an image is, the shorter the distance and higher the similarity is between two images. A tag “Yes” means an exact match. But the results are far from been impressive.
Image Hashing
It is easier for computers to compare text files than graphic ones. Hash is a unique sequence of symbols, and a special algorithm is used for converting images into strings of text. In image search, image hashing has some specifics well covered here and here.
In brief, if there are two input photos of the same person, but one image is compressed or somehow modified in another way, a hashing algorithm provides two different hashes. And by comparing the hashes, a visual search model will erroneously identify that there are two different people on the input photos. In computer vision, there are specific hashing algorithms used to avoid such an error. Nonetheless, it doesn’t yield outstanding results.
Deep Learning Can Allow Machines to Outdo Humans in Recognizing Faces
Algorithms employed within simple approaches perceive an image as a set of spots. For example, if there is a black sofa on a white background, the algorithm tries to find some images containing similar black and white spots.
More complex architectures – i.e., artificial neural networks working based on deep learning (DL) – consider a semantic meaning. They recognize meaningful objects on an image. The network structure includes multiple layers, each trained to recognize certain patterns. The deepest layer is capable of inferring the semantic meaning of an image. Roughly speaking, it is what helps computers to see images like us.
Each layer of a network provides some output or result that the next layer takes as input data. For the deepest layer, the output is called embedding. The embedding should be taught some metrics so that the last layer can deliver quality recognition results. This method is called deep metric learning.
The first powerful algorithm for deep metric learning – DeepID2 – was described in 2006. It proved that computers in face recognition had all the potential to become just as good as humans, even better. Since then, neural networks driven by artificial intelligence have dramatically evolved. Now the type of algorithm is not a big deal. Everything depends on a challenge, a chosen method, and parameters for model quality validation.
DL-Based Approaches
Contrastive Loss, Triplet Loss, CoCo Loss
Loss functions in model training serve for achieving a minimum difference between the output and the ground truth, simply speaking, what is on the image in reality. They are used to evaluate the ability of the model to predict the class of an image.
To do image retrieval tasks, a model should first learn some discriminative features. Contrastive loss is the most basic function used to teach a model to discriminate between a pair of images based on the set of features. Triplet loss works for three images.
There are more up-to-date losses, such as CoCo loss, vMF loss, and so on. The accuracy varies insignificantly, between 99,12% and 99,86%, which proves that the choice primarily depends on the type of tasks.
FaceNet
Face recognition system FaceNet was developed by Google in 2015, and it has demonstrated state-of-the-art results since then. It encompasses a set of DL-based techniques: triplet loss, semi-hard negative mining, offline sampling, and so on.
The network receives a triplet of input images: Anchor, Positive, and Negative. Here, Anchor and Positive are the photos of the same object or face, while Negative is a photo of a different thing. The choice of a mismatching photo is not random and relies on a special technique. The network learns to bring a matching photo closer to the anchor image and increase the distance to a mismatching one:
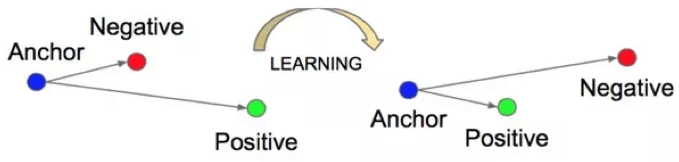
Source: arxiv.org/
Let’s get back to LFW and check the results that deep learning-based FaceNet can deliver:

For sure, the quality has increased dramatically. Even mismatching photos are very similar to originals by gender, ethnicity, or age. A human observer could mistake one person for another, to say nothing about a computer.
Conclusion
The creation of FaceNet led to fundamental changes in computer vision. The focus has shifted from innovative algorithms to powerful data. Now, a valuable client’s dataset provides the most significant advantage in building custom solutions.
InData Labs’ experts have deep domain know-how in different aspects of computer vision. We approach each client individually and choose the most relevant techniques and methodologies to create and deliver custom computer vision solutions for solving real challenges and increasing business value.
Start Your Computer Vision Project with InData Labs
Have a project in mind but need some help implementing it? Drop us a line at info@indatalabs.com, we’d love to discuss how we can work with you.