
Falls are common and expensive, especially when it comes to seniors. They’re the reason for trips to the emergency rooms and hospital stays. Slipping on a wet floor or tripping on a wrinkled carpet can cause injury or even disability. That’s why senior fall detection and prevention with action recognition technology is important. They have the highest risk of death or serious injury resulting from a fall and the chances of negative outcomes increasing with age.
According to WHO, falls are life-threatening or fatal for adults older than 60. Even minor trauma can lead to hospitalization, long-term consequences, or irreversible damage. Statistics show that one out of four older people falls each year and 20 percent of falls end up with a serious injury, such as broken bones or a head injury. Therefore, having fallen once, a senior may be afraid to perform their everyday duties, and such inactivity may eventually lead to a greater weakening of the body and susceptibility to injuries.
WHO and CDC research presents numerous factors that can multiply the chances of falls, including alcohol or substance use; underlying medical conditions; lower body weakness; poor cognition or vision; unsafe environments; use of medicines, and many others. Such a long list emphasizes that creating a safe environment is of great importance to prevent falls. It is desirable to have regular eyesight checks, take vitamin D, determine in what way each medicine affects you and minimize home hazards.
The problem is no matter how thoroughly we try to prevent falls, it’s a phenomenon that may take place everywhere and at any moment. Therefore, one should consider in what way they can be assisted in case of a fall. The good news is that senior falls are predictable and preventable with computer vision technology.
If a senior falls and can not stand up on their own, it is this very technology that comes to the rescue. Specific systems and fall detection devices for seniors are designed to automatically detect a fall and ask for help. Without immediate emergency help, even lying on the floor may lead to serious health complications, such as pneumonia, dehydration, hyperthermia, or muscle necrosis. To prevent it, in case of a fall, a senior alert system for fall detection makes a call to the center where specialists talk to you evaluating the severity of an accident. If you are unconscious, the call is automatically redirected to the emergency services, and your location data is sent as well.
Now let’s dive in tech details and see how the technology works:
Action Detection Technology
Today, algorithms based on CNN are good at recognizing and understanding what’s happening in the images. Tasks like face classification and recognition, CNN can already do better than humans. That’s especially useful during video processing, because video displays moving visual media. One can think it’s easy to understand what’s in the video if we process every video alone. But that’s not true, if we aim to understand actions in the video.
For example, the task of stair fall detection is similar to what we’ve described above. We could solve it using pose estimation by defining all the key points and analyzing the position of a person in the video. If the person sits or lies in the video, we can suppose he/she fell. But how could we understand, if the person fell down or he/she was sitting and having a coffee on the stairs? To see it more clearly, we need not only to process every shot but see how they’re connected.
There are a number of tasks depending on what result one has to achieve. Let’s consider the three major ones in more detail: action recognition, temporal action localization, and spatio-temporal action localization. Notably, understanding what people are doing in the video is usually of greatest interest. The same is implied in the mentioned tasks; however, almost all ideas can conceptually be extended to encompass animals/robots or more generic tasks.
Human Action Recognition Technology
The task of human action detection in the video is known as action recognition. This task is the principal one and, if equalled to image processing, resembles Image Classification. It is assumed that an algorithm input contains a small video only with the process of performing an action chosen from a predetermined list of actions.

Source: Unsplash
Similar to Image Recognition, we distinguish the epoch before CNN and after. Nevertheless, attempts to achieve the same colossal increase in the models’ quality failed. The first models with a CNN base were inferior to classic algorithms based on the use of hand crafted features. Furthermore, the model that functioned on one shot wasn’t far behind those analysing the interaction of several shots. It led to the conclusion that the features generated by CNN don’t detect action specificities.
The first CNN model to achieve state-of-the-art results was Two Stream Network, which in addition to rgb images uses Optical Flow as secondary flow. Optical flow is our mathematical definition of how we believe movement in subsequent frames can be described as densely calculated flow vectors for all pixels.
Another breakthrough in human action recognition technology became the use of 3D convolutions. Despite the fact that the C3D model neither managed to achieve state-of-the-art results nor surpassed the hand crafted features based model, subsequently, the approaches described in it were widely disseminated.
Since then the two approaches to two stream networks and 3D convolutions were combined and improved to eliminate all the defects of each approach. Further information on tech details and the models’ evolution can be found here and there.
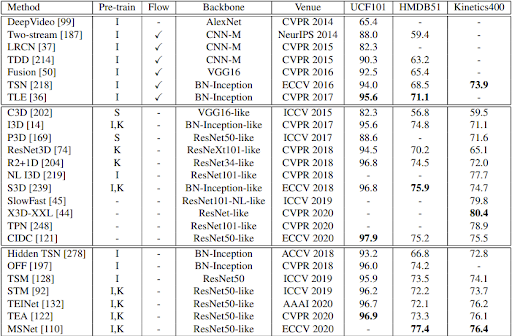
Temporal Action Localization
But what shall we do in case we have a videostream or a long video? It is similar to Object Detection but it contains a spatial coordinate instead of a temporal one. Concerning the technical component, the vast majority of algorithms are said to use action recognition features.
What are the actions and when do the actions happen? We take this task as action localization, or temporal action localization, or action detection. Although both action recognition and action localization are important tasks of video understanding, temporal action localization is more challenging than action recognition. And the relationship between action recognition and action localization is similar to image recognition and image detection. But owing to the temporal series information, temporal action localization is much more difficult than image detection.
The difficulties are as follows:
a) Temporal information. Because of the 1-dimension temporal series information, temporal action localization can’t use static image information. It must combine the information of a number of temporal series.
b) Unclear boundaries. It is different from object detection where the boundaries of the object are usually very clear, so we can mark out a clearer bounding box for the object. However, there might not be any sensible definition of the exact temporal extent of action. So it’s impossible to give an accurate boundary when the action starts and when the action ends.
c) Large temporal spans. The span of temporal action fragments can be very large. For example, waving hands can only take a few seconds while climbing or cycling can last for tens of minutes. Their spans differ in length, which makes it extremely difficult to propose suggestions. In addition, in the open environment, there are many problems such as multiscale, multi-target, and camera movement.
Although action detection has been studied for many years, it is still in the test phase of laboratory datasets, and there is no actual practicality and manufacturing. The task of understanding what the action is and when it happens in a video is very challenging. It can be seen that there is still no robust solution to this task currently. LINK
Spatio-Temporal Action Localization
And what if in the video several people are performing different actions?
Spatio-temporal action recognition, or action localization is the task of classifying what action is being performed in a sequence of frames (or video) as well as localizing each detection both in space and time. The localization can be visualized using bounding boxes or masks.
In addition, these tasks include the attempts to use other features such as the results of the model’s pose estimation, audio, depth or textual description of what’s going on in the video.
Let’s examine the example of a stair fall. It would be great to use Temporal Action Localization, but, unfortunately, this model functions slowly and badly, as it was described earlier. That’s why we may detect localization in the video with other means. For instance, Motion Detection can be used as it easily reacts to considerable picture changes between shots. Besides the mentioned models, the Object Detection model can be employed for human detection, which is more resource-demanding but produces fewer false positives.
The examined action is an easy one, thus even CNN + LSTM model can detect it, however, more complicated actions require more complex and alongside slower algorithms.
But if we take into account that the length of the videos is not long, one can detect actions with the use of the Spatio-Temporal Action Localization.
Source: YouTube
Bottom Line
We have also learned that action recognition powered by computer vision is a truly unique problem with its own set of complications.
Nowadays, detecting actions remains one of the most challenging tasks in terms of both accuracy and performance. Despite the stratospheric success of deep learning architectures in image classification (ImageNet), progress in architectures for video classification and representation learning has been slower. In resolving other tasks neural networks are able to achieve satisfactory or even better results than humans. However, action recognition is still in the prospect of reaching that goal.
Although action recognition technology is still on its way to improvement, it is a verified assist in senior fall detection and prevention of negative or even terrific outcomes. It is better to be sure that if you fall, there will always be a helping hand to come and help you cope with possible consequences. In case of a false senior fall detection (which is a very rare occasion), the call may be easily cancelled, so knowing that you will not be left alone in a critical situation will surely help you live more freely and avoid terrible outcomes.
Automatic Fall Detection for Seniors with InData Labs
Need to develop a senior monitoring and alert system for fall detection to spot falls and send for immediate help? Get in touch with our action recognition experts to see how they can help.