
Are we heading towards the future of machines that learn and perform all by themselves? With the recent advancements in deep learning, it may seem so, but some experts disagree. Human-in-the-Loop approach to machine learning is gaining popularity as the best approach to training more accurate models. What value can it bring to a machine learning project?
What does Human-in-the-Loop Mean
Human-in-the-Loop (HITL) means including human feedback into the learning loop of the machine in order to help it improve faster. In this approach, humans are involved in the training process of the algorithm by continuously tuning and testing the data.
The core philosophy of this approach is to leverage both the human and artificial intelligence to omit the drawbacks of both and get better quality results.
How big of a role do human play in such scenarios?
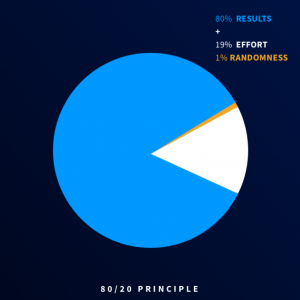
Many data scientists use an 80/19/1 approach, which is a play on the Pareto’s 80/20 rule that is often used in the business world. The 80/19/1 approach state that in 80% of the time the algorithm should be left alone to learn, while humans intervene in the 19% of the times. The remaining 1% of the input are left to randomness.
The approach of HITL is not to be confused with pure supervised learning. Yes, supervised learning is a part of the HITL approach, but it also relies heavily on active learning, where data is continuously tested, tuned and fed into the algorithm in order to achieve better results.
In a HITL approach, humans step in when algorithms are not up to the task. In other words, when the machine isn’t sure what the answer is, it relies on a human, then adds the human’s judgment to the model. This way the algorithm learns faster and the need for future human intervention is reduced.
When is Human-in-the-Loop Used
Human-in-the-loop approach is not something you would implement in every machine learning project. There are special occasions when this approach will be beneficial:
- When algorithms don’t understand the input. For example, if the algorithm has been working with pictures of cats, it might be uncertain when presented with a picture of a dog for the first time. Another example is of a chatbot that is met with a “Ciao” instead of “Hello”, “Hi”, or “Hey. To avoid mislabeling and miscommunication, data scientists set a certain threshold for the algorithm. If its certainty about an answer falls below that, the request is redirected to a human.
- When algorithms don’t know how to perform the task. This is most common for early stages of training where certain actions are not automated yet, or actions that can’t be yet automated.
- When Input is interpreted incorrectly. If the algorithm misinterpreted the input or the input was incorrectly labeled, the outcomes will be wrong as well. A human needs to intervene and correct the mistakes.
- When the cost of errors is too high. For many industries, such as medical or insurance, an ML algorithm can have absolutely no margin for error. Any room for error leads to dire consequences.
- When the area of input is rare. There are many situations where the field the algorithm is trained in is rare and there are too few training examples. In such cases, no amount of training will make the machines produce results with a high level of confidence. Humans can help further training the algorithm by correcting its mistakes.
- When there’s little data available. For example, classification of social media posts, for a new business in its early stages, by machines might not be a viable option due to the scarcity of data. Humans will make much better judgments in the early stages, but, over time, machines can learn and can take over the task.
Practical Applications of Human-in-the-Loop
The main value of the HITL approach is a shorter training time and more accurate results. In different industries that can take on different forms.
Let’s look at chat bots first. In many industries, they have replaced much if not all of the first-line customer service. Most of what they do is answering routine questions and redirect more complex issue to human operators. Chatbots are training to analyze everything a customer is writing and derive the best possible solution based on that. Sometimes, however, a customer might describe too many details.
For example, a customer might type “My server has crashed and is showing a blank screen”. The core problem here is obviously the broken server, not the screen, but the chatbot might try to offer solutions for a broken screen, which might annoy the customer. A human should step in and point out the core request in the problem.
Humans intervention plays also an important part in the training of self-driving cars. With the help of deep learning, algorithms are able to drive well already, but only in about 90% of the times. As high as this percentage is, it’s not high enough when human lives are involved.
Something as small, yet important as traffic signs can be hard for the algorithm to label because the same type sign can vary in color, size, and text depending on the country or area. Humans need to step in and correct those mistakes or they can have fatal consequences.
On a more trivial note, Facebook uses the HITL approach by including its users in the photo tagging process. Facebook’s photo recognition algorithm is pretty good: it can recognize a person in the photo you upload with 97.25% accuracy. On occasions when the algorithm is unsure, it will ask you to either confirm that the correct person is tagged or ask you to tag them all together.
Human-in-the-Loop is a Big Part of ML Future
Machine learning and AI have come a long way, and those fields will undoubtedly play bigger and bigger roles in our lives. But if we think that the AI-powered machine will replace us in more and more fields, we might be wrong.
From what we’ve seen so far, machines can learn autonomously, but only up to a certain point. To bridge the last gap between the ultimate understanding of a task or a field, the machines need humans. And even then, the machine will most likely become a helping tool for, rather than the main executor of a task.
Work with InData Labs on Your Machine Learning Project
Schedule an intro call with our machine learning consulting experts to explore your business and find out how we can help.


