
The technological advancements have set in motion a bundle of unequaled wonders to ease our lives. Image detection, computer vision, and facial recognition are all instances of trailblazing algorithms that also brought about human activity recognition. The latter is yet another tech boon rooted in the area of machine learning research.
Although its potential is yet to be discovered, it has proved useful in different fields, including sports training, security, entertainment, ambient-assisted living, and health monitoring and management.
Human pose estimation, in particular, has gained a lot of traction because of its usefulness and versatility. According to numerous studies, reliable posture labels in hospital environments can augment research and help better monitor patient clinical journeys.
On that note, let’s look into human activity recognition using image processing. We’ll also look under the tech hood of this phenomenon and how it amplifies human pose estimation.
But first, fundamentals
Before diving into the technology jungles, let’s address the obvious: What is human activity recognition and why is it important?
Human activity recognition or HAR is the process of interpreting human motion using computer and machine vision technology. Human motion can be interpreted as activities, gestures, or behaviors which are recorded by sensors. The movement data is then translated into action commands for computers to execute and analyze human activity recognition code.
What’s the big deal then? Well, just like any other AI-based subset, pose tracking promotes automation. That is, activity tracking allows both prediction and analysis of human behavior, thus unlocking unseen benefits and eliminating manual input.

Human activity recognition from video allows autonomous vehicles to sense and predict pedestrian behavior much more thoroughly – promoting more consistent driving. You can even use it to train a new employee to correctly perform a task or practice your moves when dancing or working out. Moreover, this technology can be used in many different use cases like gaming controllers, human-robot interactions, and even virtual reality scenarios. We’ll dwell on some of the most popular applications later in the article.
How does deep learning human activity recognition work?
Technically wise, computer vision human activity recognition remains a challenging domain. The complexity of activity detection and the number of inhabitants present in the analysis are the main issues.
First, the complexity of human pose estimation was approached through traditional techniques. The latter included Hidden Markov Models and Support Vector Machine techniques. However, they were unable to capture complex movements with a sequence of micro-activities. That is why researchers tapped into a recent shift in machine learning techniques and data mining. This made deep learning a predominant technology to tackle the challenge of activity detection.

The input of HAR models is the reading of the raw sensor human activity recognition dataset and the output is the prediction of the user’s motion activities. Here’s what goes in between.
All HAR systems can be grouped into two categories. The first relies on sensor-based activity recognition. It means that a human should place wearable sensors on their body for the system to collect data.
The second approach is vision-based, i.e. human activity recognition from video or images. In this case, the system gathers data with a camera to identify activities. Human activity recognition with smartphones is also a widespread data source.
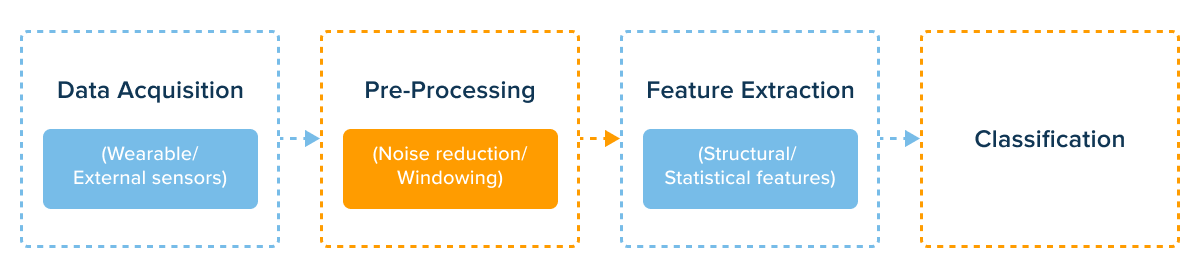
In both cases, the obtained data is processed with algorithms that then generate a series of numbers that describe each human activity in machine language.
Therefore, the step-by-step process of human activity recognition follows the steps below:
 Based on the movements, the algorithms produce predictions or insights for further analysis. Professional athletes, for example, use HAR systems to improve their performance. They can even be found in the Series 4 Apple Watch to identify falls. Thus, if the device detects a hard fall, it can help connect you to emergency services if needed.
Based on the movements, the algorithms produce predictions or insights for further analysis. Professional athletes, for example, use HAR systems to improve their performance. They can even be found in the Series 4 Apple Watch to identify falls. Thus, if the device detects a hard fall, it can help connect you to emergency services if needed.
Deep learning models for human activity recognition
Activity classification is essentially a time series problem. Time-series classification is a type of supervised machine learning. It’s used to predict future values from past data using statistical techniques, and it can be used for forecasting and offloading sensor data.
As of today, neural networks have proven to be the most effective in performing activity recognition. In particular, two approaches, including Convolutional Neural Network Models and Recurrent Neural Network Models, are the most widely used for this task.
So how does human activity recognition work using these models? Let’s see.
Recurrent Neural Network Models
Recurrent neural network (RNN) models are powerful sequence models that can handle time-series data with ease. The main differentiator of these models is that they are based on predefined parameters. Thus, they feed on input data with fixed dimensions and output the result, which is also fixed.
The advantage of RNNs is that they provide sequences with variable lengths for both input and output. This makes them a perfect option for discerning movements.
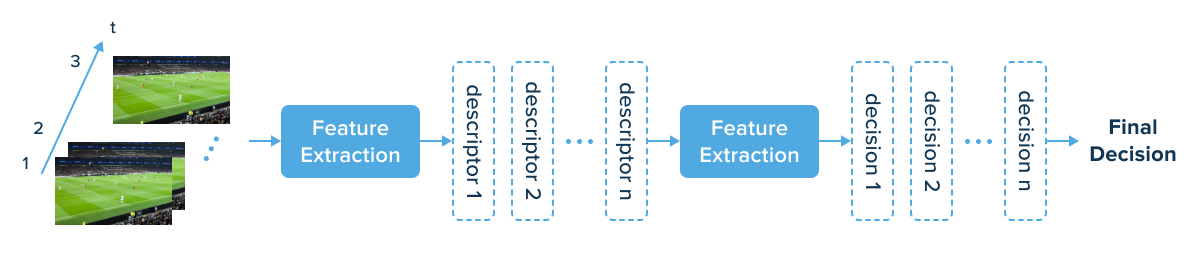
Here’s how recurrent neural networks work to classify the activity:
- First, the system vectorizes the video files and calculates descriptors (they are needed to describe elementary characteristics of the activity).
- The system then forms a visual bag of words to present the data for further classification.
- Descriptors are then fed into the input layer.
- RNN layers then analyze and classify the data.
- The system outputs the result.
We can demonstrate this model by the following classifier schema:
RNNs are quite popular for the task of activity recognition. Thus, University of Michigan researchers have presented an algorithm that will help autonomous cars recognize the direction and predict pedestrian movements.
By collecting camera and GPS data, the developers created a dataset and trained a recurrent neural network to predict human movements with an accuracy of 10 cm. The model is called Bio-LSTM. It is a recurrent neural network with LSTM that can predict the location and 3D posture of a pedestrian based on the previous frame.
Convolutional Neural Network Models
Convolutional Neural Networks (CNNs) are a special type of neural network that has proven effective at processing visual data. CNNs have been implemented in image recognition, automatic number plate reading, and self-driving car software. Convolutional neural networks gained huge popularity thanks to their resilience to changes in scale, rotation, distortion, and other kinds of changes in data.
Let’s demonstrate how this model works. Last year a group of US scientists presented a 3D CNN algorithm that can reconstruct the three-dimensional pose of an animal with high accuracy. Unlike most current approaches, this method does not require markers to be attached to animals. It means that this application will be convenient for observing animals not only in laboratories but also in the wild.
To train the neural network, scientists assembled a dataset of seven million frames of synchronized video and labels with anatomical landmarks of rats from several angles. The step-by-step process follows the below milestones:
 That was a brief explanation of the main deep learning models for human activity recognition. Now let’s go over one of the most prominent examples of artificial intelligence solutions – pose estimation.
That was a brief explanation of the main deep learning models for human activity recognition. Now let’s go over one of the most prominent examples of artificial intelligence solutions – pose estimation.
What is human pose estimation?
Human activity recognition is the hotbed for many applications. Some of the most run-after ones include biometric signature, advanced computing, health, and fitness monitoring, and eldercare.
One of the main challenges in the field of activity recognition is estimating human poses. This has traditionally been done by using a hand-crafted model that requires careful initialization and parameter estimation, but thanks to recent advances in deep learning it’s now possible to use neural networks for pose tracking.

While the spike in published studies and articles happened during 2017-2019, this area of research grows each day. As such, pose estimation is a computer vision problem that aims to estimate the 3D pose of an object from a single image. It can be used, for example, to allow virtual characters to present objects in the correct orientation and position when they interact with users.
The pose itself refers to the position and orientation of an object in space. A person’s pose could be represented as a point (head pose) and two vectors (upper limbs), together with the body center.
Pose estimation for business is hard since it relies on a huge knowledge base, including geometric relationships, appearance, material properties, lighting conditions, and others.
This discipline traditionally falls into two kinds of estimation based on the number of dimensions. Thus, 2D pose estimation identifies the location of key points in 2D space relative to input data. For each keypoint, the model calculates an A and B coordinate. The goal of 2D pose estimation is to obtain the camera matrix and its inverse, which can be used as input for applications such as 3D modeling, 3D visualization, augmented reality, etc. By adding a C-dimension, 3D posture estimation transforms an object in a 2D image into a 3D object.
3D pose tracking allows developers to estimate more accurate dimensional positioning of an object. However, it’s trickier than 2D since algorithms have to factor in a slew of conditions, including background, light, and others.
Types of human pose estimation models
The modeling of the human body is the most important aspect of human pose estimation.
The three most common types of human body models include skeleton-based models, contour-based models, and volume-based models.
- Skeleton-based or kinematic models – skeleton-based pose estimation methods are different from other methods because they do not rely on object segmentation. Instead, these methods use a set of image features that encode positional relationships between parts of the body (e.g. skeletal joint connectivity information) and use the data for 2D and 3D estimation.
- Contour-based or planar models – provide a detailed 2D representation of natural body shape. The model captures the contour and rough width of the body, torso, and limbs. This helps the model to accurately represent a variety of human shapes and poses.
- Volume-based model – this model estimates the 3D structure of an object from one or more 2D images. It consists of various geometric shapes, such as cylinders, conics, and triangulated meshes. The output is then used for deep learning-based 3D human pose estimation.
Furthermore, there are two primary approaches to assessing poses. These are bottom-up models and a top-down approach. The former starts by identifying the body joint first and building a unique pose, while the latter runs a detection module to get human candidates and then locates human key points.
The bottom-up approach delivers a perfect ratio of estimation accuracy and computational cost. It is invariant to the number of human candidates in the image. At the same time, a top-down approach divides the task into easier subtasks, i.e., object detection and single-person pose estimation.
Head pose estimation
Pose tracking can also be applied to a specific part of our bodies. Thus, head pose estimation is the process of extracting head pose information from visual stimuli. It involves predicting the three-dimensional orientation of the head in a 2D image, which can be used for face recognition, emotion recognition, and gesture recognition.
This task usually comes down to identifying the head’s Euler angles – yaw, pitch, and roll. If the algorithm gives an accurate prediction of these three, it’ll find out which direction the human head will be facing.

Head pose tracking is an inherently hard task for computer vision. Even though several strategies have been developed over the years to solve this problem, it is still a research topic, especially in unconstrained situations.
Other specific tasks for pose estimation include video pose tracking, animal pose estimation, and car detection. Each of these applications comes with a unique set of constraints. The latter may stem from limited labeled data (for animals) or pose occlusions (for videos).
Importance of human pose estimation
Prior to pose tracking, machines perceived humans as square, thus overlooking human body language. Intelligent pose estimation allows computers to obtain a higher level of reasoning. It’s also one of the fundamental components of markerless motion capture (MoCap) technology. Character animation and clinical examination of gait disorders are just a few of the possibilities for MoCap technology.
However, only real-time human recognition can help us accrue a wealth of benefits. Putting an estimate on how many people are in a room – just by looking at their silhouettes – can be very useful in understanding the intricacies of human activity. Being able to track people reliably across time and space has applications in law enforcement, health care, sports performance, workplace ergonomics – the list goes on.
Let’s take Waymo self-driving cars. These autonomous vehicles are inherently safe to be deployed on roads. However, Waymos tend to get hit by human drivers due to the unexpected stop caused by a pedestrian crossing the street. But with pose estimation, Waymos will be able to avoid fender-benders by better predicting pedestrian behavior.
Let’s assess the viability of deep learning human activity recognition by looking at other real-life applications.
Human activity recognition using image processing: applications
Pose estimation is an important prerequisite for human behavior understanding. Therefore, its techniques found many applications in surveillance, gaming, animation, and others. And as human activity recognition using smartphones projects become popular, it’s even easier to use them as an alternative for HAR (provided they are equipped with a rich set of sensors). Let’s see how this fact has promoted en-masse applications.
Human-computer interaction
Human-like androids used to be a sci-fi concept. Today, we already have androids like Hanson Robotics’ Sophia and Tesla Bots. However, the process of inventing a humanoid is complex (to say the least). 3D pose estimation is essentially designed to help computers gain a high-level understanding of human behavior. Using the pose estimation API, a robot can perform tasks more accurately, especially if it also can understand the 3D poses, actions, and emotions of people.
When a robot recognizes the 3D position of a person prone to falling, for example, it can take appropriate action. Furthermore, if helper robots can sense 3D human poses, they can better socially connect with human users. Another popular application of pose tracking is training robots to learn certain crafts.
Video Surveillance
Abnormal activity recognition is another area of research. Nowadays, video surveillance is of great significance for public safety. To maintain public security, governments tend to install CCTV cameras to monitor crowd activity. However, while cameras produce a great amount of visual data, we need an intelligent and automatic system to recognize violent or suspicious behavior. And this is where motion tracking comes in.

Based on the position of key points, the system can generate alerts in real-time when a potential assault is in progress. The identification of people with hands up or laying down can also be related to an alarming situation as some studies suggest.
Sports performance analysis
Tracking the position of human joints can be used to track a variety of sports performance metrics which are extremely useful for athletes and coaches. Kinematic pose rectification, for example, can be used for instant training feedback and quantitative assessment of an athlete’s performance. Also, motion assessment can be used to evaluate and educate amateurs in swimming, Tai Chi, and soccer.
For AI-powered fitness, pose tracking can help guide end-users through a number of workouts. This will help ensure compliance with the safety rules and real-time feedback for at-home workouts.
![]()
Psychology
Applications of 3D human body poses have also been made to human health. Thus, this technology can be potentially used in telehealth. For example, a doctor will be able to perform a quantitative motor assessment directly in a patient’s home. Recognition of atypical behavior is also important for autism detection since early detection is important to make the person’s life better. Overall, motion tracking can identify the mental states of people as well as their emotional wellbeing.
Fashion and retail
Virtual try-on is a new way to bring fashion e-commerce into the 21st century. Rather than buying online and hoping for the best, users can see how a garment will look on their own body before making a purchase. This technology is not only useful for people with disabilities who have difficulty dressing or purchasing clothing, but it can also help consumers make better purchases in general. 3D pose estimation is the backbone for virtual try-on by rotating the item synchronously to face angles or body shape.
The bottom line
Computer vision human activity recognition is an exciting area of research. It is set to revolutionize multiple industries, including healthcare, sports, and entertainment. But while the prospects seem bright, 3D pose estimation still remains a challenging task. A lack of in-the-wild 3D datasets, large searching state space for each joint or occluded joints can hamper the speed and accuracy of motion identification.
Nevertheless, deep neural networks have substantially increased the output by automatically learning features from raw data, making motion tracking a promising application.
Develop pose estimation solutions with InData Labs
For more info on human activity recognition and video analytics, please take a look at our blog.