
Apart from performing for our clients, InData Labs data science team is keen on taking part in top notch data science competitions, for example, Kaggle Competition.
The team has recently shown one of the best results in Quora Question Pairs Challenge on Kaggle. The challenge is remarkable for a number of interesting findings and controversies among the participants, so let’s dig deeper into the details of the competition and create a winning formula for data science and machine learning Kaggle competition.
About Quora Question Pairs Kaggle Competition
Quora is a Q&A site where anyone can ask questions and get answers. Quora audience is quite diverse. People use it for studying, work consultations and whenever they have second thoughts about almost anything. Over 100 million people visit Quora every month, so it’s no surprise that many people ask similarly worded questions. Multiple questions with the same intent can cause seekers to spend more time finding the best answer to their question and make writers feel they need to answer multiple versions of the same question. That’s why the goal of the competition was to predict which of the provided pairs of questions contained two questions with the same meaning.
Participants were offered a training data set that contained more than 404 thousand question pairs. After getting a closer look at the examples, you’ll understand that the task is very complicated even for humans.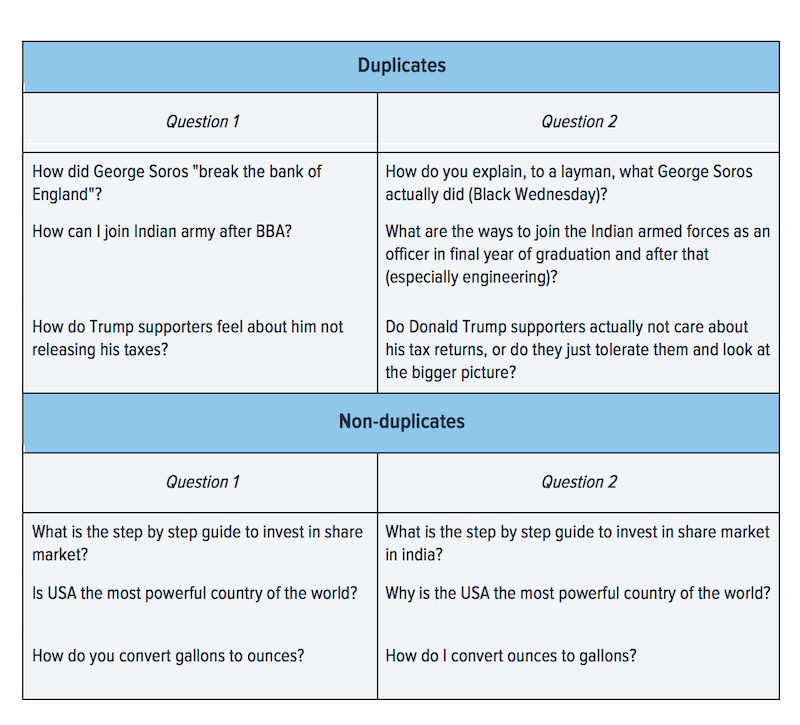
First three question pairs were preliminary marked by Quora as duplicates, whereas pairs 4-6 were marked as non-duplicates. As you can see the questions from duplicating pairs look totally different and the non-duplicating questions may differ with just one word. This is one of the main specifics of the data set that makes the task pretty difficult for NLP technologies.
Unique Characteristics of the Data Set
Right after the start of the Kaggle competition participants started sharing interesting findings about the data set. Some of the findings could really skew final results of the competition, others were just amusing. Here are the most commonly met ones:
- Incorrect Labeling
As recognized by the organizers “The ground truth labels on this data set should be taken to be ‘informed’ but not 100% accurate, and may include incorrect labeling. We believe the labels, on the whole, to represent a reasonable consensus, but this may often not be true on a case by case basis for individual items in the dataset.” In reality there were a lot of cases when question pairs included inaccurate and ambiguous tags. Certain compared questions were only partially included. Here is just a couple of examples: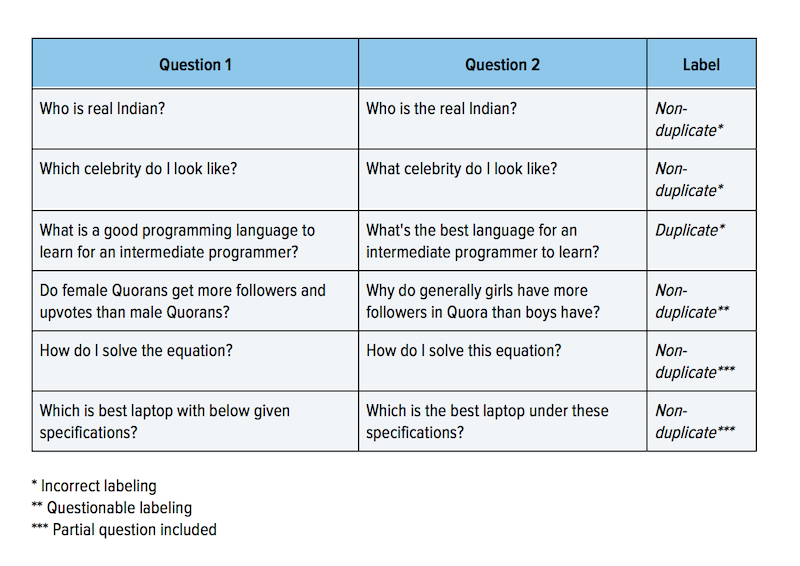
- A lot of Questions about India
Although training set contains many different questions about various topics, it catches the eye, that a lot of questions are about India. Certain NLP models that were trained on such data could start giving a lot of value to the words specific only to the questions about India. This means that such models can skew their answers in the questions not related to India. That can cause bias in case models that were trained on this data were used on other data. However, it didn’t happen to us, since the test dataset also included a lot of questions about India.
- Training and Test Data Sets were not Equally Distributed
This data set characteristic is associated with the ID of each question in a training set. IDs are additional info, but in machine learning competitions they often contain non-evident useful information. For example, let’s suppose older questions have smaller IDs. This way we can see how the number of duplicates changes with time.
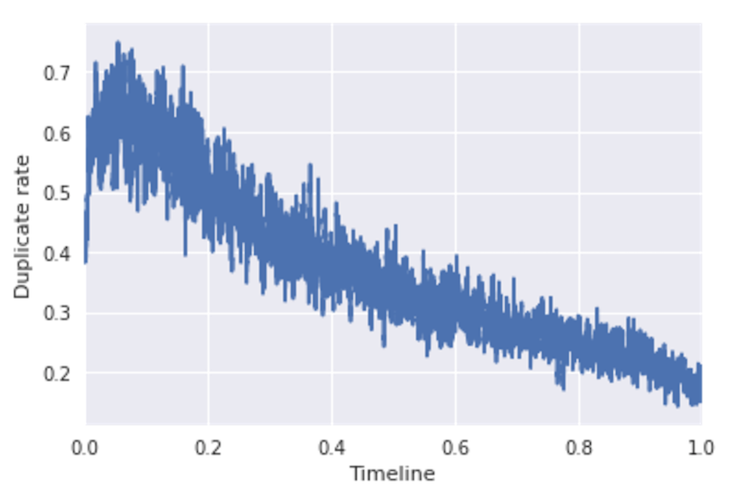
As we can see in the diagram, the number of duplicates is decreasing over time. Unfortunately, unlike the training set, test set does not contain questions’ IDs, that is why we can’t use this information, although some of the contestants tried to restore the questions’ IDs for the test set. The characteristic is important since it is a common practice to use older data in training sets and newer one in test sets. All of it makes us think that the number of duplicates in the test set is less than in a training set.
It is very important to know in advance in case the duplicates’ distribution is different in test and training data sets since the quality metric used in this solution is very sensitive to those distribution changes. For example, in case the model is processing the test data and it is hesitating it will probably choose to mark the pair as a non-duplicate since it already knows that the number of non-duplicates prevailed in the training set. And in case the distribution in a test data set is different, the model will most likely be wrong.
Magic Features
Contest organizers expected that participants will be preliminary using NLP features in their solutions. But it turned out that data set structure itself contained valuable features.
Two of them turned out to be the most defining.
1. In order to use this valuable information, it is convenient to present the data set as a graph. It can be done in a number of ways. For example, let’s build a graph where every record will be represented with two nodes connected with an edge. At the same time, one node corresponds to one question from the data set. Let’s imagine the data set contains only seven records:
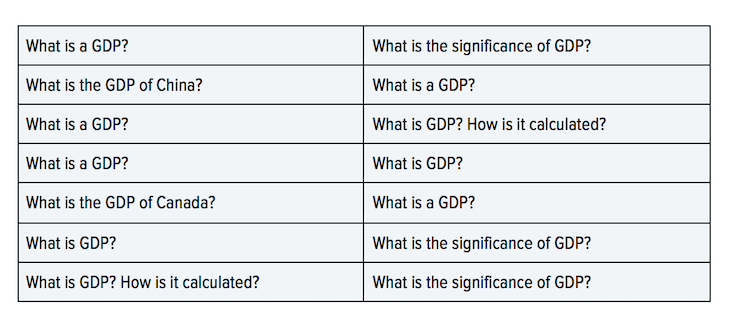
The graph will look the following way:
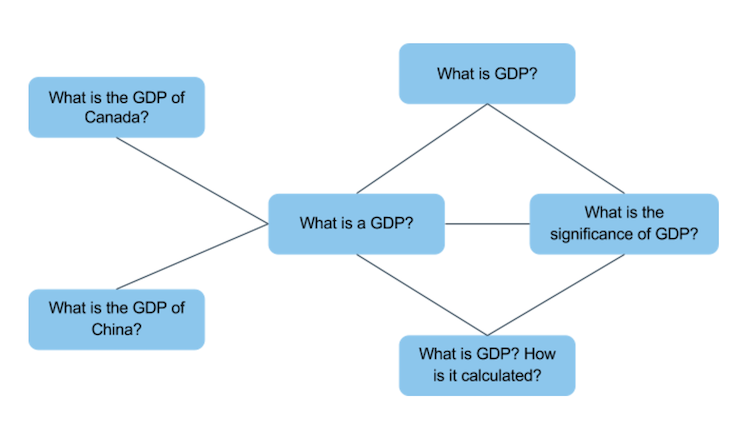
Now we can calculate the number of “common neighbours” for every question pair from the data set. “Common neighbours” will be the questions that are neighboring in the graph with questions from one record. For example, the first record from our data set will have two of such “neighbours”:
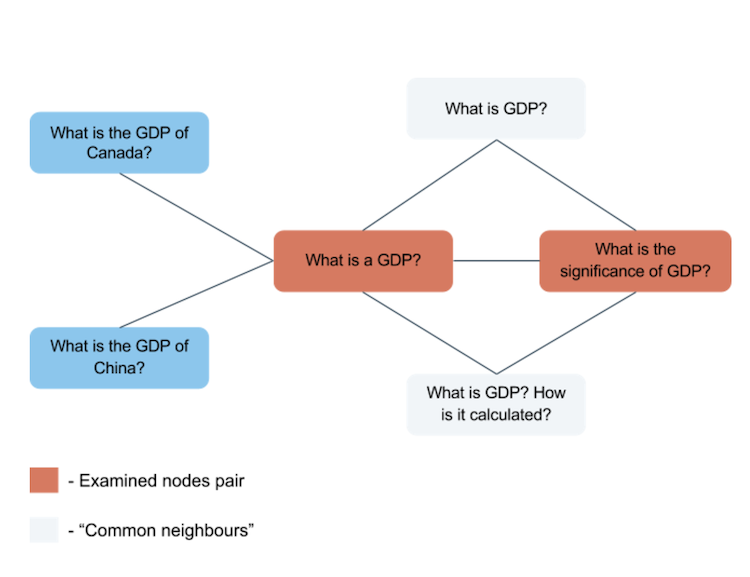
The number of such “neighbours” turned out to be a very strong magic feature. It can be seen in the following diagram. It shows the correlation between duplicates and non-duplicates in the training set for the records with a particular number of “common neighbours”.
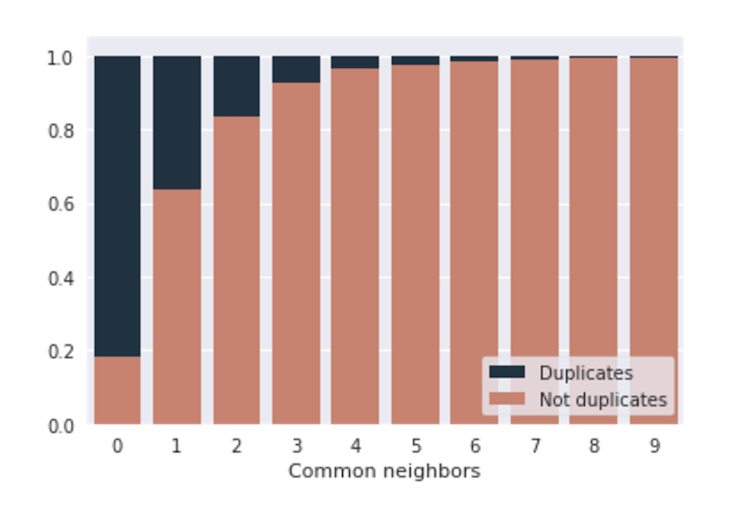
So, around 80% of the records that score zero in this feature are duplicates, and those that have one “neighbour” have less than 40% chance of being duplicates.
2. Another structural characteristic is the frequency of a question. Let’s calculate the number of incident edges for every node of the graph (in other words: we’ll calculate how often each question occurs in the data set). This way every record will contain the number of occurrences for each question. We can use the minimum/maximum number of these occurrences, their average value or difference between them. Such features also turn out to be very strong and improve model’s performance.
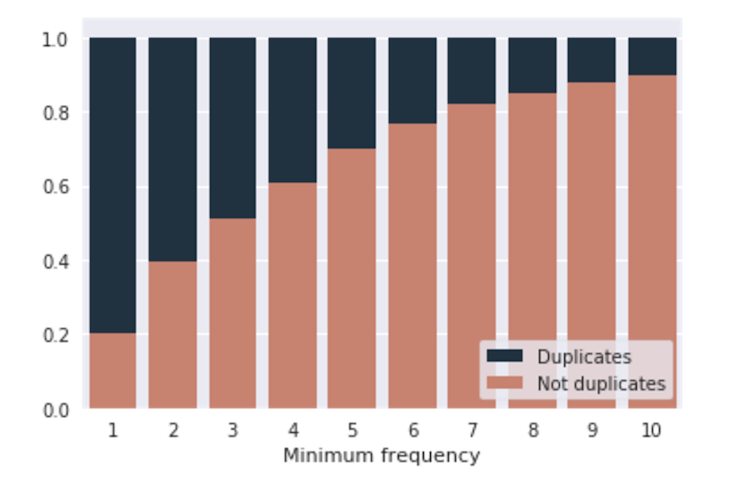
These features were referred to as “magic” ones during the competition since they turned out to be quite strong. Many participants were surprised when they found out that useful information can also be found in data set’s structure. Also, it wasn’t clear from the beginning whether such features would be useful for competition organizer’s business. Moreover, certain NLP models (TF-IDF, for example) implicitly use question’s number of occurrences, this means that such models can improve their quality of prediction only based on the specific characteristics of a particular data set.
Of course, there are many other ways of finding useful information in data set’s structure, but those were the most powerful ones in a particular Kaggle competition.
Our Solution to Quora Question Pairs Kaggle Competition
- Deep Learning
Taking task’s specifics into account, it is worth mentioning that a lot of hopes of both participants and organizers were placed into deep learning. It is true that in many cases deep learning models have shown better results than the models using hundreds of handcrafted features (Quora has already been using one of such models). This is why we started the work on our solution with deep learning models.
- Word Vectors (Embeddings)
Modern deep learning models are represented by deep neural networks that get raw data as an input (questions’ texts) and produce the necessary features themselves. The problem is that neural networks prefer to work with sets of numbers (vectors) rather than with raw texts. For example, words “dog” and “puppy” have similar meanings, but they are not meaningful for a computer. The words have different lengths and letters, so the computer won’t see any similarity. And in order to solve this task, it is important to understand whether the words are similar or not. Word2vec approach can help with that. Its essence can be described in one quote: “You shall know a word by the company it keeps” – Firth, J. R. 1957. Word2vec modifies words into vectors, this way the words that are used in similar contexts, have similar vectors. Using word2vec we can transform raw texts into a set of vectors, that can be easily used in a neural network.
It is worth mentioning that it is hard to train word2vec and other embeddings since we need a text corpus the size of Wikipedia. That is why the majority of competitions’ participants use pre-trained models.

- Neural Networks
Siamese neural networks are the best solution for such task. They are used when we need to identify how similar the two objects are. Such neural networks have two identical inputs that are used to extract the features. On the next level, either those features are used to calculate the similarity metrics or all the features are combined and passed over to a fully connected layer. After the experiments were over, we chose the following architecture of a neural network:
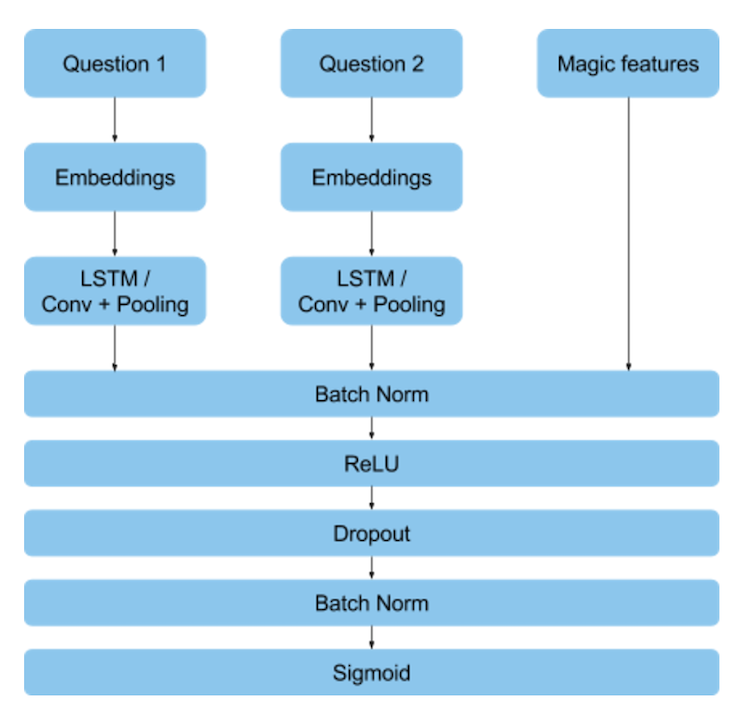
Important remarks:
- Apart from having two inputs for the compared questions, our neural network had a third input for handcrafted features, which is not very typical for deep learning models. It was made due to the “magic features”, that had a strong influence in a given data set.
- We used two neural networks in our solution. In the first one, we used LSTM in order to extract information from the questions. In the other one, we used a couple of convolution layers followed by Global Max Pooling.
- The architecture we chose is not so “deep”. It can be explained by the fact that deep neural networks need A LOT of data to work properly. Our data set was not so big and its labeling was rather noisy. So there was a high chance of model overfitting, especially when using LSTM.
- Some more ideas worth experimenting:
- LSTM with attention
- Character-Aware Neural Network
- Triplet Neural Network
- Target encoding
After the experiments with neural networks were over, it became evident that they were not enough. In addition to the data set being too small and noisy labeled for deep learning models to show their full power, there were problems with transforming the text into vectors. The data set contained a lot of mathematical formulas, rare abbreviations, and spelling mistakes. This is why part of the information about a question went missing, which made the work of neural networks very complicated.
- Gradient Boosting
And finally, the time for a favorite tool of data science competitions participants – gradient boosting. The model has proved itself to be very strong and stable to labeling noise.
We used the following features for gradient boosting:
- Length of questions, number of words, number of words except for stopwords
- The number of capital letters, question marks, quotes etc…
- Indicators for questions starting with “Are”, “Can”, “How” etc…
- Similarity measures on Word embeddings (Word2Vec, FastText, Glove)
- Word Mover’s Distance
- Similarity measures on bag of character n-grams (including TF-IDF)
- Jaccard, Canberra, Chebyshev similarities
- Abhishek’s and Mephistopheles’s shared features
- PageRank
During this competition we’ve also got to test the new gradient boosting library LightGBM. It turned out that it as precise as the old one XGBoost or even better, but it is way faster. So many participants used LightGBM in their final models.
We’ve also used out of fold neural networks predictions as boosting features. It was only left to balance the difference of target distribution between train and test sets, pick model’s hyperparameters and validate the results. Such model was more than enough to get a silver medal on Kaggle.
Quora Question Pairs Kaggle Competition Winning Recipe
Here is a short guide to what you should have done to win this competition:
- The more the better
We’ve only used around 70 handcrafted features and 3 models in our solution. However, the winners have used 1000+ features and combined hundreds (up to a thousand) of models. It often happens that the more of different models you combine in your solution, the higher are the chances you’ll win a Kaggle competition. - Advanced graphical features
Graphical features we’ve already mentioned were not the only way to use the data set’s structure. Winners managed to find a lot more of such features and used them in their models. - Local rescaling
The main idea is that the whole data set can be divided into a number of smaller data sets. Each of them will possess different duplicates distribution, so it is necessary to balance these data sets in different ways. - Prediction postprocessing
One more way of improving the result was to correct the predictions the model has already made. For example, we could use the transitivity characteristic. In case question B is a duplicate to question A, and question C is a duplicate to question B, it is evident that questions A and C are also duplicates.
There is a solution by Alex that is worth mentioning. It uses just one model – convolutional neural network (its architecture is quite similar to our solution). The model shows good accuracy and at the same time has really good productivity, as against to other solutions. This model is the most suitable for real-life use cases and is worth the attention.
Conclusion
Kaggle Competition is always a great place to practice and learn something new. However, the best solution on Kaggle does not guarantee the best solution of a business problem. The example of Quora Question Pairs Kaggle Competition illustrates how important it is to be very careful and considerate while preparing a training data. In case the data set characteristics we’ve described are simulated and not typical for the whole Quora question base, it means that participant’s solutions are not applicable in real life. But still the participants have proved that the hacks to finding duplicates among questions can not only be found in texts themselves. InData Labs, a data science consulting company, wishes you good luck with your experiments. Have fun!


