
“How can we ensure the success of our machine learning project?”
Your business has asked this questions. Your competitors have asked this question. Unfortunately, there is no straightforward answer, but a good candidate could be feature engineering.
Some data scientist described it as a bottleneck, other as a superpower. Either way, all of them agree that it is a vital part of any successful machine learning project. Let’s dig in to see what business value feature engineering has to offer.
What is Feature Engineering
Feature engineering is the process of identifying features with predictive power from raw data sets. The role this process plays in a machine learning project is irreplaceable; it has a direct impact on how good the final predictions will be.
Some even call feature engineering an art. And truth be told, they are not far off in their definition. As we’ll illustrate later, feature engineering takes a lot of domain knowledge and machine learning skills, but ultimately it’s tied together by creativity.
If done correctly, feature engineering increases the predictive power of machine learning algorithms, and can even offset the adverse effects of a poorly chosen model or wrong parameters. But let’s not jump ahead. Before understanding the how let’s look at the why.
Why Feature Engineering is Important
The success of a machine learning project can be boiled down to two things: well-chosen algorithm and good data. To pick a suitable algorithm can be difficult but not impossible. Many different algorithms can solve the same problem with equal success.
The problem of data, on the other hand, might be more difficult to deal with. Many data sets often come in raw formats that have no or little predictive value. The data is also often unstructured, stored in multiple formats, contains missing values, etc. In other words, it has nothing to teach an algorithm.
Algorithms need structure. Feature engineering is the tool that creates or reveals that structure. The whole process of feature engineering is based on answering the question of “How do you get the most out of your data?”
The quality and quantity of your engineered features will influence the results of your predictive model. Poorly made features will naturally produce poor results.
On the other hand, well-executed feature engineering can weigh up for other subpar factors of your machine learning project:
- Wrong models: even if you choose an algorithm that is not entirely optimal for your machine learning problem, you can still get good results. Feature engineering means well-structured data, which most models can pick up on.
- Wrong parameters: the same can be said about parameters. You do not need to work as hard to optimize parameters.
- Simpler models: with well-executed feature engineering, you can also get away with using less complex models that are faster to run, easier to understand and easier to maintain.
All these 3 points entail better, more robust results and shorter time-to-market for your machine learning project.
How Does Feature Engineering Work
Let’s look at a real-life example taken from a public Kaggle competition.
The primary goal of the competition is to predict what customers will return to make a purchase. The teams are given a data set of customer purchasing data gathered over a year. The set contains around 350 million rows and has the following features:

Although this dataset contains a lot of information about each customer and their shopping habits, on their own, each of these features hold little predictive value. What can we do about that? For ones, we can combine some of them to form new features. For instance, if put together, the features “Manufacturer”, “Date of purchase” and “Customer ID” can tell us who buys from the same manufacturer more than once.
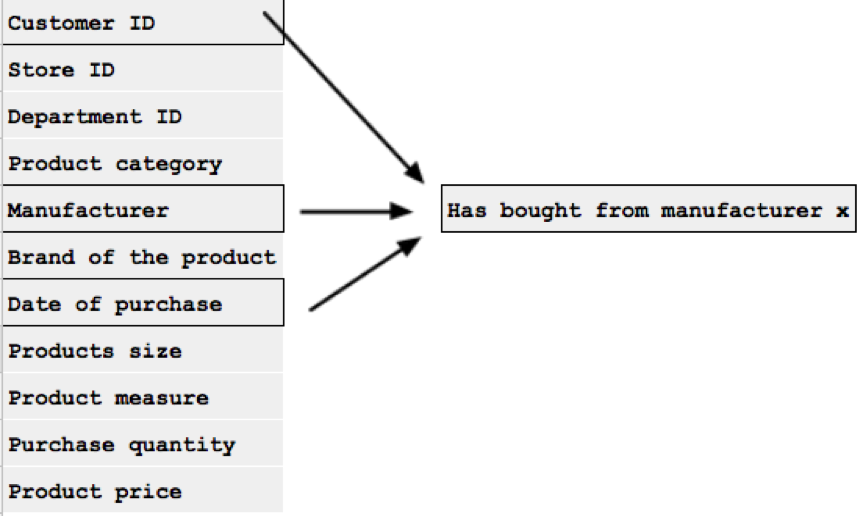
This new feature can be called “Has bought from manufacturer x”. It can be a simple 1 or 0 (yes or no), or we can split it into multiple new features that include time periods. Another useful feature we can generate is “Total amount spent” which can be made by combining “Customer ID”, “Product price”, “Product quantity”, and “Brand”. Some customer might not shop that often but they spend a lot of money once they do, and that can also signal customer loyalty.
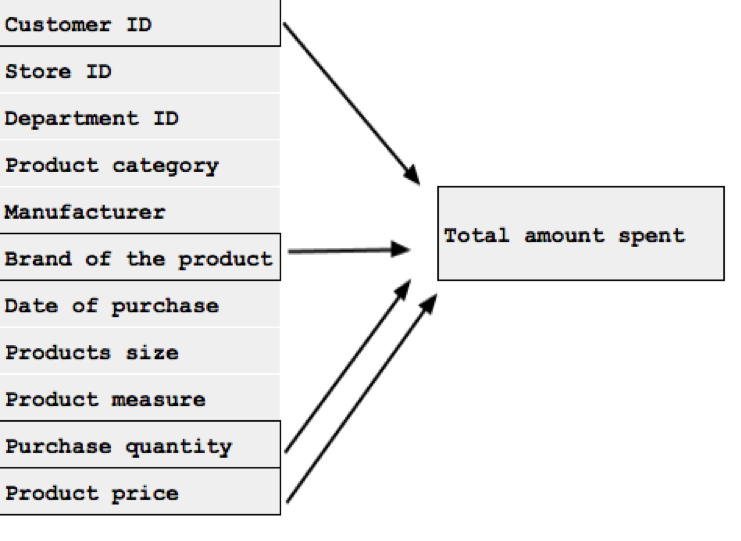
Now that we have our two features we would want to check their predictive power. This means running our model to see if it produces satisfactory results. If not, we will have to go back to the data sets to look for more features.
This is the process of feature engineering. The basic steps can be narrowed down to:
- Brainstorming features
- Creating features
- Checking if the model produces satisfactory results with the chosen features
- If not, go back to step 1
The domain knowledge and creativity are mostly required in steps 1 and 2. Patience is needed for steps 3 and 4. It’s a lengthy process.
Up to 70% of the time in a machine learning project can be spent on feature engineering. That number might be lower if the data contains a lot of raw features (obtained directly from the dataset with no extra data manipulation or engineering), or it might be higher if the data scientist needs to work on deriving features.
The data scientist working with feature engineering has to consider the underlying machine learning problem when designing features.
The key questions that a data scientist needs to ask herself during feature engineering process in order to do it well are:
- What are the essential properties of the problem we’re trying to solve?
- How do those properties interact with each other?
- How will those properties interact with the inherent strengths and limitations of our model?
- How can we augment our dataset so as to enhance the predictive performance of the AI?
Automated Feature Engineering
The time-consuming aspect of feature engineering makes it a perfect candidate for automation. There have been a number of attempts to automate feature engineering. Most of them can:
- generate new features automatically
- know which algorithms call for feature engineering
- understand what types of feature engineering work best with what algorithm
- systematically compare engineered features and algorithms to find the best match
Such systems are more efficient and repeatable than manual feature engineering. By spending less time on steps 1 and 2, you can build better predictive models faster. The results of automated feature engineering are also much less error-prone.
However, automated feature engineering is not intended to replace data scientist but rather assist them.
Automated feature engineering does, on average, find more features. But what features should be included in the training of the final model should be determined by domain experts.
Domain experts are often better than machines at suggesting patterns that hold predictive power. For example, a tool can recommend around 40.000 features but domain experts will pick only 100 that are relevant.
Work with InData Labs on Your Machine Learning Project
Schedule an intro call with our machine learning consulting experts to explore your business and find out how we can help.


