
Deep learning is largely responsible for today’s growth in the use of AI. Despite the deep learning challenges of implementation, the technology has given computers extraordinary powers, such as the ability to recognize speech almost as good as a human being, a skill too tricky to code by hand. Deep learning has also transformed computer vision and dramatically improved machine translation. It is now being used to guide and enhance all sorts of key processes in medicine, finance, marketing—and beyond.
In this article, we’ll discuss the features that have earned deep learning it’s popular status as well as current challenges that need to be addressed before deep learning can reach its full potential.
Strengths
Let’s first take a look at the most celebrated benefits of using deep learning.
Advantages of Machine Learning
Feature engineering is the process of extracting features from raw data to better describe the underlying problem. It is a fundamental job in machine learning as it improves model accuracy. The process can sometimes require domain knowledge about a given problem.
To better understand feature engineering, consider the following example.
In the real estate business, the location of a house has a significant impact on the selling price. Suppose the location is given as the latitude and the longitude. Alone these two numbers are not of any use but put together they represent a location. The act of combining the latitude and the longitude to make one feature is feature engineering.
One of deep learning’s main advantages over other machine learning algorithms is its capacity to execute feature engineering on it own. A deep learning algorithm will scan the data to search for features that correlate and combine them to enable faster learning without being explicitly told to do so.
This ability means that data scientists can sometimes save months of work. Besides, the neural networks that a deep learning algorithm is made of can uncover new, more complex features that human can miss. About deep neural network advantages and disadvantages you can read below.
Best Results with Unstructured Data
According to research from Gartner, up to 80% of a company’s data is unstructured because most of it exists in different formats such as texts, pictures, pdf files and more. Unstructured data is hard to analyze for most machine learning algorithms, which means it’s also going unutilized. That is where deep learning can help.
Deep learning algorithms can be trained using different data formats, and still derive insights that are relevant to the purpose of its training. For example, a deep learning algorithm can uncover any existing relations between pictures, social media chatter, industry analysis, weather forecast and more to predict future stock prices of a given company.
No Need for Labeling of Data
Getting good-quality training data is one of the biggest problems in machine learning because data labeling can be a tedious and expensive job.
Sometimes, the data labeling process is simple but time-consuming. For example, labeling photos “dog” or “muffin” is an easy task, but an algorithm needs thousands of pictures to tell the difference. Other times, data labeling may require the judgments of highly skilled industry experts, and that is why, for some industries, getting high-quality training data can be very expensive.
Let’s look at the example of Microsoft’s project InnerEye, a tool that uses computer vision to analyze radiological images. To make correct, autonomous decisions, the algorithm requires thousands of well-annotated images where different physical anomalies of the human body are clearly labeled. Such work needs to be done by a radiologist with experience and a trained eye. According to Glassdoor, an average base salary for a radiologist is $290.000 a year, which puts the hourly rate just short of $200. Given that around 4-5 images can be analyzed per hours, proper labeling of all images will be expensive.
With deep learning, the need for well-labeled data is made obsolete as deep learning algorithms excel at learning without guidelines. Other forms of machine learning are not nearly as successful with this type of learning. In the example above, a deep learning algorithm would be able to detect physical anomalies of the human body, even at earlier stages than human doctors.
Efficient at Delivering High-quality Results
Humans need rest and fuel. They get tired or hungry and make careless mistakes. That is not the case for neural networks. Once trained correctly, a deep learning brain can perform thousands of repetitive, routine tasks within a shorter period of time than it would take a human being. The quality of its work never diminishes, unless the training data includes raw data that does not represent the problem you are trying to solve.
Deep Learning Challenges
As new use cases for deep learning are uncovered, so are the challenges that need to be addressed.
The Need for Lots of Data

“How much data is actually enough to train my algorithm?” What are the deep learning challenges?
This are the questions that are most frequently asked by anyone who works with deep learning algorithms. There is no straight-forward answer, unfortunately, but as a rule data scientists say that the more powerful abstraction you want, the more data is required.
In the case of neural networks, the amount of data needed for training will be much higher compared to other machine learning algorithms. The reason is that the task of a deep learning algorithm is two-folded. First, it needs to learn about the domain, and only then solve the problem. When the training begins, the algorithm starts from scratch. To learn about a given domain, the algorithm needs a huge number of parameters to tune and “play around with”.
To understand this better, think of a deep learning algorithm as a human brain. We need a lot of experiences to learn and deduce information about the world around us before making any decisions. We learn that the stove is hot by putting out finger on it, or that snow melts at warm temperature when we try to bring it home. Similarly, a neural network learns about what makes a stock price of a given company increase or decrease by going through the data set again and again.
Neural Networks at the Core of Deep Learning are Black Boxes
One of the most discussed limitations of deep learning is the fact that we don’t understand how a neural network arrives at a particular solution.
It’s impossible to look inside of it to see how it works. Just like in a human brain, deep learning has advantages and disadvantages, and the reasoning of a neural network is embedded in the behavior of thousands of simulated neurons, arranged into dozens or even hundreds of intricately interconnected layers.
Together they form a complex web where inputs are sent from one level to the next until an overall output is produced. Additionally, there is a process known as back-propagation that tweaks the calculations of individual neurons in a way that lets the network learn to produce the desired output faster.
Even though neural networks produce great results, the lack of transparency in their “thinking” process makes it hard to predict when failures might occur. The same argument also renders them unsuitable for domains where verification of the process is important. One good example is medicine.
Take, for example, Deep Patient, a deep learning program that was applied to patient records of more than 700.000 individuals at Mount Sinai Hospital in New York. After a long training period, Deep Patient was able to detect certain illnesses better than human doctors.
On one hand, this is great news. On the other, if a tool like Deep Patient is actually going to be helpful to medical personnel, it needs to provide the reasoning for its prediction, to reassure their accuracy and to justify a change in someone’s treatment. Without the justification, it is difficult to gain the trust of patients or learn why any mistakes in diagnosis were made.
Overfitting the Model
Overfitting refers to an algorithm that models the “training data” too well, or in other words one that overtrains the model. Overfitting happens when an algorithm learns the detail and noise in the training data to the extent that negatively impacts the performance of the model in real-life scenarios.
Overfitting is a major problem in neural networks. This is especially true in modern networks, which often have very large numbers of parameters and thereby a lot of “noise”.
How do you know if your model is overtrained? When the accuracy stops improving after a certain number of epochs.
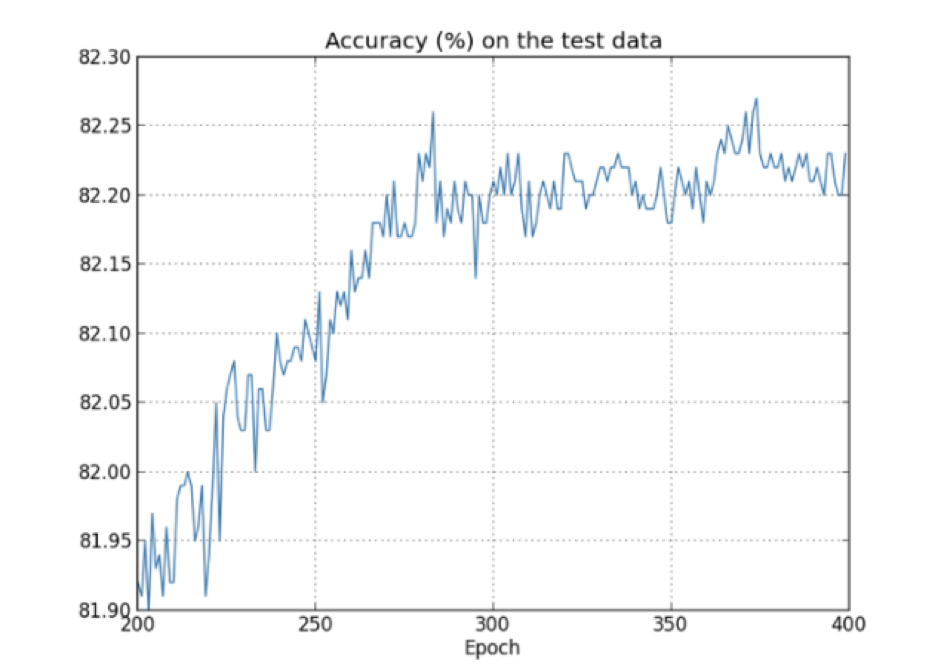
In the picture above, we can see that the accuracy does not increase after about 275th epoch but only fluctuates between about 82.15% and 82.25%. Most likely this means that the model is being overtrained after the 275th epoch.
Lack of Flexibility
Despite the occasional warnings of AI taking over the world, deep learning algorithms are pretty simple in their nature. In order to solve a given problem, a deep learning network needs to be provided with data describing that specific problem, thus rendering the algorithm ineffective to solve any other problems. This is true no matter how similar they are to the original problem.
Let’s look at a trivial, yet a familiar example of a deep learning algorithm distinguishing a chihuahua from a muffin.
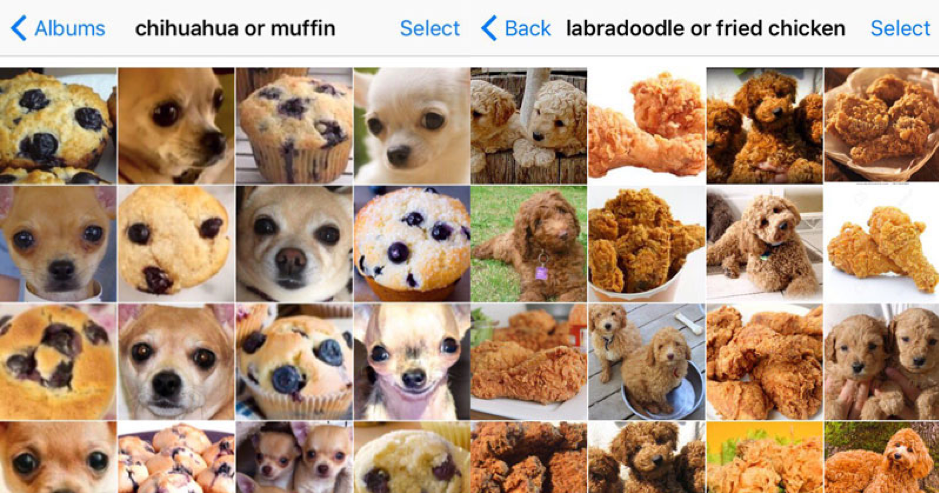
The algorithm was successful at telling apart the tiny canine and the sugary pastry, but if put to a similar test – distinguishing a dog breed from a food type – of labradoodle and fried chicken, the same algorithm would most likely produce poor results.
Conclusion
The points presented above illustrate that deep learning has a lot of potential, but needs to overcome a few challenges before becoming a more versatile tool. The interest and enthusiasm for the field is, however, growing, and already today we see incredible real-world applications of this technology.
There are, of course, the more consumer-related applications such as the helping voices of Siri and Cortana, Google Photos’ tagging feature, Grammarly’s proofreader, and Spotify’s music recommendations.
However, a bigger impact of deep learning is to be found in the business world.
Deep learning algorithms are applied to customer data in CRM systems, social media and other online data to better segment clients, predict churn and detect fraud. The financial industry is relying more and more on deep learning to deliver stock price predictions and execute trades at the right time. In the healthcare industry deep learning networks are exploring the possibility of repurposing known and tested drugs for use against new diseases to shorten the time before the drugs are made available to the general public.
Governmental institutions are also turning to deep learning features for help to get real-time insights into metric like food production and energy infrastructure by analyzing satellite imagery.
The list can go on, but one thing is clear: given the use cases and enthusiasm for deep learning, we can expect large investments to be made to further perfect this technology, and more and more of the current challenges to be solved in the future.
Work with InData Labs on Your Next Brilliant Idea
Have a project in mind but need some help implementing it? Schedule an intro call with our AI software development engineers to explore your idea and find out if we can help.


