
Data warehouse automation has made a backbone of a new way of creating databases to generate data-controlled strategic insights. But why did it become so critical?
With a swift growth of data science algorithms, enterprises get opportunities to boost the nature of their commercial activities and identify the front and light spots of every functional unit. However, to succeed, the analytics-ready data should be derived and stored in a suitable format to come up with business-driven decisions.
The traditional database structure is associated with a long and pricey development process, which may not yield results in variable economic conditions. Moreover, most corporations experience difficulties interconnecting their in-house ecosystems with their analytics data storage cannot consolidate the number of incomplete statistics.

Source: Unsplash
These problems reinforce the shortage of database computerization. Data warehouse automation technologies allow for data manipulation smoothly and efficiently, reducing the number of errors and inaccuracies in BI reports.
What is data warehouse automation and how it works
Before discussing the essentials of data storage robotics, let’s begin with the enterprise data warehouse notion to clear a vision of the topic discussed.

Data warehouse automation implicates the data capture methods relying on machine-driven manners to computerize the stages of data warehousing approaches: from designing to structuring and incorporations. It accelerates and enables the retrieval of information from diverse locations and transforms it into a unified platform, where it’s arranged for further visualization.
To gain insight into how the system operates, it’s critical to understand how data storage manages data. Corporate metadata archives are an epitome of complexities with intricate structure since they’re made to transfer, arrange, save, and scrutinize intelligence. Each of these responsibilities demands separate layers that take care of its tasks. Generally, there are three kinds of data warehouse robotics:
- Single-tier structure. This is a pretty old-fashioned approach to data repository deployment. It concentrates on creating a reliable data set and reducing the volume of data saved. The database is linked directly to the intelligence interface, where specialists can make requests.
- Two-tier architecture. This layer is a mediator between the user interface and corporate data hosting. Data marts are the subsets of the centralized database entailing department-specific info. Making data mart is less intense-consuming, and such an approach enables addressing the concern with querying. Business units can easily access the required details without navigating the murking water of reports.
- Three-tier architecture. This is an advanced level of handling and synchronization of information diversity. Companies rely on multidimensional OLAP cubes, known as online analytical processing, to show the data assets in different dimensions. While standard data repositories allow for data representation in a simple form (e.g., Excel), OLAP makes it possible to compose the information in mixed sizes, alternating it.
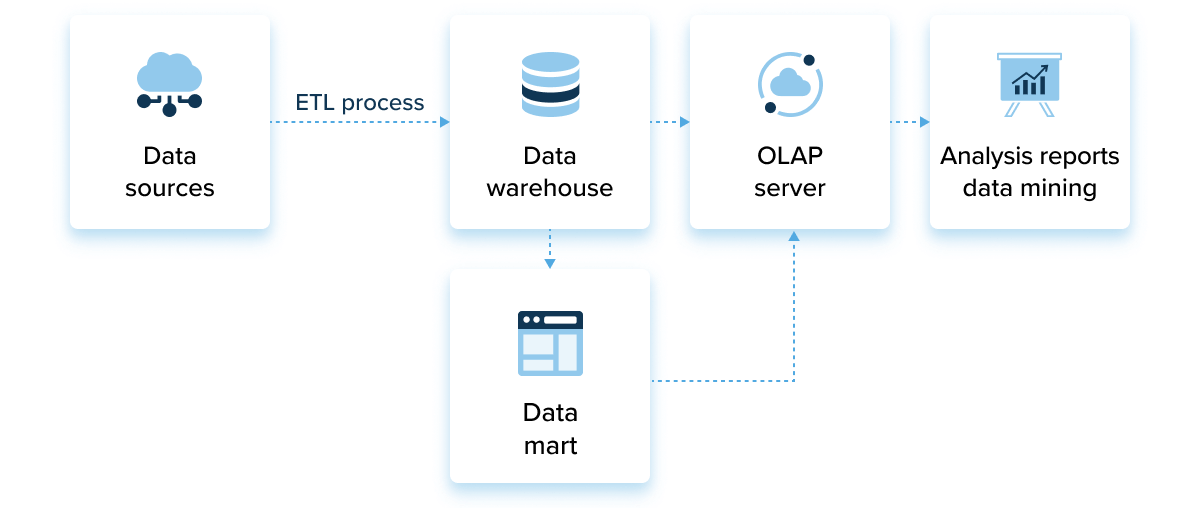
Data warehouse automation networks are built to accelerate and streamline the data computerization. This can be performed in several ways, but most enterprises use ETL tools to get the job done. Let’s briefly discuss how the ETL procedure is carried out.
Software engineers rely on extracting, processing, and migrating tools to spruce up all the data.
- Extraction. The data is kept in diversified systems and derived into a unified database. It’s better to appeal to data extraction services to guarantee successful data extraction.
- Transforming. The referred data is modified to the unified pattern to ensure all the information responds to each other.
- Loading. The newly-transfigurated info is sent to the corporate repository.

Generally, software engineers need to initially determine ETL processes to transmit statistics from databases to advanced analytical tools. However, deploying ETL manually (via SQL or Python) is a long-term process resulting in inefficient data warehouse automation management.
In contrast, modern data warehouse automation solutions provide low-code and agile methods for summarizing and transferring diverse enterprise data from internal and external data sources to a unified database.
When enterprises require data warehouse automation: checklist
In digital-centric reality, bridging the gap between technology and business becomes crucial. Digital transformation is intertwined with enhanced efficiency and reduced costs — thus, there is always a right moment to capitalize on robotic solutions. However, another question is how to comprehend the deficit of data storage digital transformation? To answer, here are the ten checkpoints every C-level executive should account for before initiating automated data warehousing projects:
- It’s hard to log in statistics in all the branches.
- Current data warehousing activities have labor-intensive nature.
- Inability to handle the enhanced data volumes from a slew of line-of-business software.
- Reliance on conventional data control systems and appliance of Excel worksheets for presenting.
- There are delays and lessened data quality due to manual interventions and limited personnel.

Source: Unsplash
- It’s tough to merge and process data represented in different formats.
- There is a lack of access to historical data at any given time.
- There is a lot of time required to figure out which data should be used for modeling rather than operating on data.
- There is no clear vision of data applied to real-time analytics and reports.
- It’s challenging to modify reports/information requirements to meet business and regulatory demands.
Consensus on the statements discussed proves the demand for automation in data warehouses.
Data warehouse automation benefits
The leading gain of automated operational databases is accelerating and robotizing the administration and monitoring of information across the entire lifecycle: from source analysis to testing and documentation, while ensuring statistics quality and consistency. So let’s see how exactly all-sized businesses can profit from data warehouse automation solutions.
Freeing up time/resources for higher-level activities
Before actually making sense of data, there are many preparation steps required. Initially, data analysts deal with free-flowing, raw, and unshaped data from varied system resources. Such a data set is full of errors, bias, and duplications.

Source: Unsplash
Experts must perform a thorough review to understand which data is matched and can be applied for further processing. BI team performs data flow mapping exercises using different tools, such as Microsoft SQL, to fulfill these tasks. Unfortunately, owing to its labor-intensive and manual nature, specialists lack detailed information obtainable for scrutiny and presenting it to tech leaders. Irrelevant intelligence results in cost overrun and false assumptions.
Data warehouse automation app is built to accelerate the portion where executives are trying to supply the analytics pipeline with valid facts. It provides for delivering structured and cleaned information into a unified location just in a couple of clicks.
As a result, it takes talented people to focus on the things that truly matter instead of running repetitive tests.
Gain more valuable business inputs
Successful business intelligence implementation depends on a deep interpretation of data points that will tell how well the enterprises work and what should be done to bring added commercial value. However, getting all the tech leaders to concur on the statistics on which decisions will be made is pretty arduous.

Source: Unsplash
Data warehouse automation systems create opportunities to quickly unite distinct parts of information, move them through the entire BI development cycle, and submit outputs to end-users to see if the defined cluster of parameters contributes the good insights. If there is no deep insight perception, a novel group of data parameters could be set up until the story appears. Besides, the results of data analysis can be obtained within days rather than months.
Improved performance by reducing time to-value
Machine-driven databases make organizations more agile in decision-making thanks to faster implementation and smooth entry to readily accessible records. This allows companies to rapidly respond to economic phenomena without financial cost.
For example, by applying data warehouse automation tools, logistics managers can accelerate the identification of the reasons for supply chain disruptions thanks to access to well-formed BI reports. Hence, the decisions made will cogitate market prospects thanks to improved impact analysis.
Easy way to maintain compliance
Privacy and security are the keystones of every firm actively involved in sensitive data administration, especially in hacker-prone industries, such as healthcare and finance. Therefore, businesses must adhere to regulatory compliance and safeguard client details. Self-acting data repositories can assist enterprises in handling legislation by automatically recording the data. It enables monitoring and registering of all data-related processes while increasing reports transparency.
5 efficient data warehouse automation solutions
Take a look at the latest data warehousing solutions and see what suit you best:
Amazon Redshift
Amazon Redshift is a widely-used data warehouse automaton optimization tool. It’s a cloud-based analytical and BI tool providing users with some exciting features, such as:
- Unlimited functionality
- Parallel data processing
- Column data storage
- Query optimizer
The service allows for requesting a mass of organized and partially-structured data. In addition, the solution easily integrates with numerous business tools and applications and relies on AWS architecture to boost client experience.

Source: Unsplash
Oracle
This user-friendly cloud-enabled solution assists developers in creating data-driven software and advanced BI models. Among the most prominent functionality are the following:
- Machine learning analysis
- Data visualization
- Auto-tuning
- Query optimization
The service maintains various workloads simultaneously (e.g., analytical SQL, machine learning, graph) and can process requests across varied data formats. In addition, it guarantees advanced levels of data protection by encrypting data, running thorough testing, and carrying out threat discovery.
Snowflake
Snowflake is the enterprise-level data warehouse built as a service in the Amazon Cloud. It’s capable of running any workload, allowing secure access to all business information, and delivers high-performance analytics for diverse enterprise needs.
One of the key differentiators of this service is decoupling this storage and compute. Its significant features include data and object cloning, virtual compute warehouse, recovery system objects, and change data capture. The Snowflake architecture can be split into three specific areas:
- Database storage. The service recognizes structured and unstructured information in its internally optimized, columnar format.
- Query processing. It employs compute and memory resources submitted by Virtual Warehouses to execute and process requests and data operations.
- Cloud services. This is a group of supporting services that coordinate activities across the platform, from client logging to query streamlining.
Google BigQuery
Google BigQuery is designed to instantly process requests on massive structured datasets. The service assists data warehouse administrators in discovering, implementing, and detecting data management tools.
It allows storing and scrutinizing the information within BigQuery or employing BigQuery to log your data where it saves. Federated queries enable interpretation of data from external locations while streaming maintains continuous statistics updates.
In addition, BigQuery ML and BI Engine tools make it possible to analyze and understand the requested data.
The most prominent features involve:
- Serverless architecture
- Multi-cloud capabilities
- Built-in machine learning and AI integrations
- Spreadsheet interface
ActiveBatch
ActiveBatch is an end-to-end solution allowing for data warehouse automation optimization and facilitating ETL processes within a real-time database. It offers a Service library to incorporate intelligence virtually. It gives full API availability allowing users to load and carry out WSDL, SOAP Web Services, RESTful Services, etc.
Among the most useful functionalities are:
- Advanced scheduling (allowing for initiating ETL procedures according to environmental conditions).
- Auditing and Governance (it helps optimize business policy across the organization).
- Privileged access management
- Ability to add multiple checkpoints to data warehouse operations (it allows users to restart the steps without affecting the entire workflow).
Each solution has its specificity and winning strategies that should be applied on a case-by-case basis. The cost of a data warehousing automation project may vary from $20K to $20M. The final price is driven by the experience of data warehouse automation companies and the toolset defined.
The role of AI for data warehouse automation

On the one hand, automated data warehousing lays the ground for successful AI implementation since it stores clean and structured data. On the other hand, AI in data warehouse automation and machine learning aims to advance the opportunities of information warehouses, making those more accessible and operable.
Instead of inputting long and complex queries in SQL, data analysts can rely on natural language algorithms. The crucial role of intelligent data management tools is to identify data utilization patterns that define who is accessing information, how it’s used, and when.
The modern enterprise data store is a crucial element of AI-based applications. This combination ensures that business information is protected and can be available by cloud-based platforms for getting insights.
After the ETL process, the data can be employed to develop AI models and feedback loops that steadily process new outputs to reduce model bias and drift. Finally, the information gathered by state-of-the-art EDW can be turned into predictive analytics, opening up opportunities for corporations to make AI-enabled apps that are used across the business units.
Wrapping up
Today the world continues to digitize. Modern data warehouse automation tools go hand in hand with cutting-edge technology and ever-evolving business requirements. This allows businesses to adjust their decision-making profitably and effectively. By automating data repositories, companies can improve ROI, save time, and boost business intelligence and data quality possibilities.
Author Bio
Yuliya Melnik is a technical writer at Cleveroad. She is passionate about innovative technologies that make the world a better place and loves creating content that evokes vivid emotions.
Data warehouse automation with InData Labs
Looking for a reliable technology vendor to assist in data warehousing? Schedule a call, and our consultants get back to you with an offer.


