
Credit: Getty
The Internet has dramatically increased the pace at which our language changes. In fact, every year hundreds of new slang words appear. Thanks to social networks, new terms and acronyms can go viral overnight.
Here are some examples of the words that originated from the Internet in the recent years:
- prt: (acronym) please retweet,
- bae: (noun) baby/babe hybrid to refer to your boyfriend or girlfriend,
- derp: (exclamation) used as a substitute for speech regarded as meaningless or stupid, or to comment on a foolish or stupid action,
- unlike: (verb) withdraw one’s liking or approval of a web page or posting on a social media website that one has previously liked,
- tl;dr: (acronym) short for “Too long; Didn’t read”
…some of them became popular enough to officially end up in the Oxford Dictionary (Source)!
What Does It All Mean for Social Media Analytics Companies?
Language is becoming a fast-moving target for social media analytics companies. With all the new terms and no small amount of slang, jokes, and sarcasm social media data is difficult to interpret even for the human brain, let alone artificial intelligence. The majority of text analysis tools rely on dictionaries to define topic or sentiment, that’s why these tools work well unless an unknown word is met.
When it’s absolutely clear that conventional text analysis tools are helpless, we offer our clients to create domain-specific models that will work exceptionally well in their context. Our models learn different English, some can easily understand teens slang on Instagram, while others have no problem with conversations on gaming forums.
How We Create Models for Domain-specific Text Analysis?
If you learn Spanish, listening to Spanish speech every day is very helpful. The process of machine learning is somewhat similar. To create a domain specific model, we start from collecting a big learning sample. Saying big I mean really big – tens of millions of texts or billions of words. To get a proper model the learning sample must contain professional terms or slang typical for your industry. For example, if you need a model that can analyze client’s opinion about new features of your product, you need to collect real customer reviews for the learning sample, so that model could learn their language. We usually leverage APIs of social networks for that purpose, gathering posts and comments from topic-related social media groups, blogs, and forums.
After collecting online conversations we divide the acquired stream of text into tokens (separate words). The process is called tokenization.
Tokenization example
| These derp dances bring me to life |
| These | derp | dances| bring | me | to | life |
Not to confuse a model with a big variety of forms of the same word, we reduce the number of forms of a word to one common base form. The process is called stemming and lemmatization:
Stemming example
bringing, brings >>> bring
Lemmatization example
brought >>> bring
After text preparation, the big (unannotated) text corpus is used for training word embeddings. Word embeddings is a geometric way to capture the meaning of a word via a low-dimensional vector. We use Word2vec or GloVe for training and using word embeddings. The model can define semantic proximity of different words.
Example: relationship between word pairs
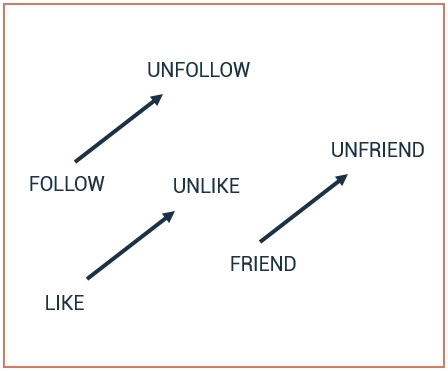
Interestingly, word embeddings are related to how the human brain encodes meaning. Analyzing millions of texts it learns that the meaning of ‘bae’ is close to ‘baby’ or that ‘derp’ is equal to ‘stupid’ or ‘foolish’ and etc. This way machine is ‘learning slang’. However, this unsupervised approach doesn’t allow us to capture text sentiment or define a topic. For these popular tasks, we need to build another model utilizing labeled texts and supervised approach.
If your sample data is limited the final model can be built using support vector machine. Given a set of training examples, each marked for belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples into one category or the other. This model is looking at words in isolation, ignoring the order of words, thereby important information can be lost.
If you are lucky enough to have a lot of labeled data (at least several thousand messages per topic or per sentiment), you can use deep learning architectures like a recurrent neural network. Such models can learn difficult language structures and recognize how words compose the meaning of longer phrases.
Deep learning for sentiment analysis example: negative sentiment comes out on top over positive sentiment
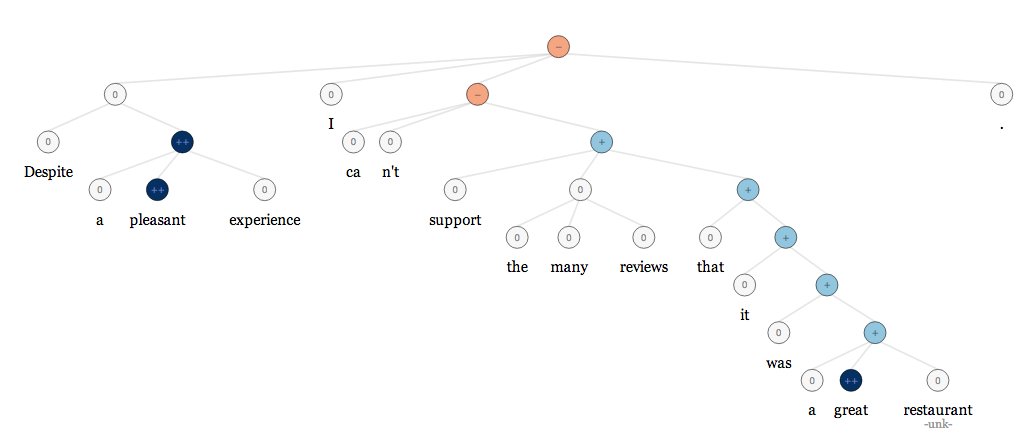
Source: http://nlp.stanford.edu/sentiment/index.html
Conclusion:
- To build a model that can understand cool kids’ social media slang you’ll need a big learning sample made up of real social media messages (tens of millions of them).
- “Yaaaaaas”, a machine can learn social media slang as well as any other type of domain-specific vocabulary. As we can’t rely on dictionaries to build such models, we recommend training word embeddings, so that machine could define semantic proximity of words itself.
- Whenever it’s possible we recommend using deep learning architectures for sentiment analysis. Deep learning allows capturing difficult language structures like ‘neither … nor’, ‘despite …’, ‘… but …’ etc. and gives us hope that machine will be able to recognize sarcasm and jokes 😉
Want to be the first to read our next great article? Subscribe to our blog.
Already have a project in mind? Let’s talk.
InData Labs helps tech startups and enterprises explore new ways of leveraging data, implement highly complex and innovative projects, and build breakthrough AI products, using machine learning, AI and Big Data technologies. Our core services include Machine Learning Consulting, Big Data Engineering, Data Science Consulting.

