
Big Data collection is the lifeblood of modern business processes. But how is Big data collected by companies? We’re about to find out.
By 2025, experts expect an influx of over 463 exabytes of data per day. If we translate that into DVDs (you remember those?), we’ll get over 212 million of them. Hence, companies need a robust collection and analytics ecosystem to make sense of this avalanche of information. This acute demand gave birth to numerous Big data collection tools and techniques.
With that said, let’s review the process of Big data collection. We’ll also go over the most popular Big data collection methods and tools.
What is Big data and why is it important?
We come across this phenomenon a lot these days. This fancy term denotes a combination of structured and unstructured data coming in at high speed and in very large volumes. However, traditional processing tools are unable to discern this information. That is why companies use robust Big data collection tools to implement insights into statistics, analysis, forecasts, and decision-making.

Source: Unsplash
Big data also helps analyze all relevant factors and make the right decision. It assists in building simulation models to test your decision, idea, or product. That is the main reason why 97.2% of companies invest in artificial intelligence and Big data.
Big data collection companies pull the input from a gamut of sources, including:
- Internet of Things (IoT) and connected devices;
- social networks, blogs, and media;
- company data, including transactions and customer profiles;
- tool readings like weather stations
- healthcare data such as EMRs and medical imaging.
Why else is Big data important? Let’s see.
Benefits of Big tech data collection
The collection of Big Data doesn’t boil down to the amount of information. The importance lies in the way companies make use of it. Thus, analytical systems help organizations uncover hidden insights in material and identify new business opportunities.
Cost savings
Topping the list of benefits is cost reduction. Big data is a big cost-cutter due to its prognostic ability. This benefit is visible in Big data retail use cases where it’s used to save product return costs. Usually, the cost of product returns is almost twice as high as that of the actual shipping. That is why retailers are always looking for ways of optimizing expenses. Big data collection tools can pinpoint the items with the greatest possibility of return. It allows companies to take proactive measures to optimize losses and costs.

Source: Unsplash
Better decision making
The collection of Big data coupled with real-time analytics allows us to process new trends fast. Big data collection tools like Hadoop help companies generate insight immediately. This translates into faster and intelligent decision-making. A prominent example is the use of Big data in medicine.
A white paper by Intel dwells on how four hospitals have been using data from a variety of sources. It helps them predict the hospital loads daily and hourly.
Fraud prevention
Data and analytics can also help companies glean actionable insights to avert fraud. For example, organizations can process consumer trends to identify and prevent suspicious activity. Thus, systems can flag even minor differences in a credit activity as potential fraudulence.

Source: Unsplash
Increased sales and better customer experience
Data analytics companies in the USA have also been helping agencies better define products and services. The diversity of information empowers all levels of the sales process. It improves the accuracy of marketing campaigns and improves sales lead data. Also, real-time information streams allow for identifying customer sentiment. This, in turn, embeds customer feedback into the decision-making process.
Overall, the collection of vibrant information flows promotes business growth. By establishing a comprehensive view of processes, organizations can use various types of data to their advantage.
Top Big data collection methods
Typically, Big data collection architecture revolves around specific kinds of information. This includes:
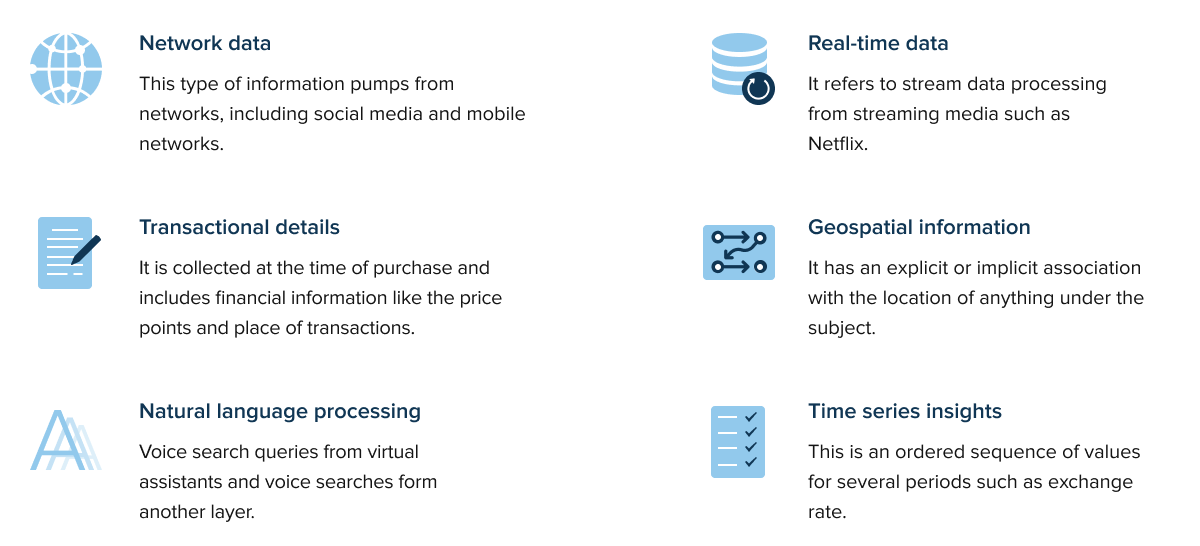
This batch of information is then fed into analytical systems to generate valuable insights. The more information an organization collects about a user’s preferences, the better algorithms can turn that information into actions. But how do companies collect it? Today, there are quite a few Big Data collection examples.
We’ll have a look at the most popular ones below.
Asking your customers directly
In most cases, companies ask users for permission to use their personal information. It usually takes the form of a privacy policy. It spells out the company’s methods to gather electronic customer information.
Cookies
Cookies are small text files that store information about our previous actions on websites. They can include user preferences, viewed items, and input text. Cookies also gather the user’s IP address and location as well as OS and browser version.
Email tracking
This source of insights refers to monitoring opens and clicks of emails. This helps companies follow up with offers, partnerships, and others. Most email tracking tools capture data on open rates and user interaction, which informs marketing decisions.
![]()
Source: Unsplash
Loyalty cards
These are part of an incentive scheme where customers accumulate credits for future discounts. Loyalty programs reward and encourage repeat customers. Most importantly, it stores your purchase history. It means that cards help retailers understand people’s behavior. After, they shape it by targeting advertising and special offers.
Gameplay
Game data is another example of Big data collection techniques. By including analytics in the game, companies can assess players’ behavior. In-app purchases, game deletion, failed levels – all of these are tracked by a company. The insights are then used to enhance the gameplay.
A prominent example of powerful Big data infrastructure is tech-savvy giants like Amazon and Apple. They build up information to create a “360-degree” view of their customers. They turn insights into personalization engines and provide customized buying experiences.
How is Big data collected: Step-by-step
Raw data is like diamonds. Before becoming precious stones, they have to go through multiple stages of mining, crushing, and cleaning. Likewise, random information has no value. Value-added Big data should be well-structured, cleaned, and analyzed. Let’s have a look at the main steps of Big data collection.
Step 1: Extraction/Retrieval
This step unfolds the cycle. It has to do with retrieving unstructured or poorly structured data from various sources. It is then sent to centralized locations for storage or further processing. Unstructured sources may include web pages, email, documents, PDF files, scanned text, and others. Centralized storage can be on-premises, cloud-based, or hybrid. However, this step doesn’t include processing or other analysis. Organizations can also buy data from DaaS companies and use data extraction tools.

Source: Unsplash
Step 2: Collection
In general, this step is similar to the first one. In this case, it is a constant and systematic approach to gathering and measuring information from a variety of sources. Unlike the first step, it is performed on a regular basis to get a complete and accurate picture of an area of interest.
Step 3: Storage
Then, you will need a compute-and-storage architecture to manage huge-scale datasets. There are three main ways to store such an amount of data. Hard disk drives, RAID, etc. are among the most popular ones due to the media’s lower cost. Companies also use public and private clouds.
Also, storage comes with object and file-based systems. The latter doesn’t limit specific capacities and allows for a terabyte or petabyte sizes.
Step 4: Cleansing
This step helps eliminate errors and inconsistencies that occurred in the database. When combining multiple sources, duplicated or mislabeled pieces are a common thing. Also, erroneous information affects the accuracy of algorithms and the analytical value.
There aren’t many ways to clean the data of such magnitude. The biggest obstacle is its variety. Different types of errors like incompleteness and value conflicting may co-exist and affect the analysis result. KATARA, ML algorithms, and parallel cleansing systems are some examples of Big data cleaning systems.
Step 5: Reorganize data
The next step involves reorgs of information for more convenient use. The reorganization aims to enhance system performance and reclaim the memory space. It also helps engineers improve data availability, query performance, and response time. This procedure is especially important for mission-critical workload environments.

Source: Unsplash
Step 6: Verify data
Checking input for accuracy is another milestone in the life cycle. The verification process is what ensures consistency and a sense of purpose. Based on your requirements, you can perform either full verification or sampling verification. In the second case, a small sample of the data is checked, which is less time-consuming.
Step 7: Analysis
Gathering valuable assets is an important step in the data lifecycle of any company. However, it’s not enough to accumulate real-time information. You should also process it to test your business hypothesis or a course of action. To do that, you can leverage one of the most popular Big data collection methods.
Data mining
This method targets previously unknown patterns in large bodies of information. It also comes complete with statistical and mathematical methods. For businesses, data mining is a valuable tool that identifies patterns and relationships in data to empower decision-making.
This method is one of the most widespread and is applicable to a large number of industries. Banks often use this method to analyze the transactions for fraud detection or the probability of loan repays.

Source: Unsplash
Cluster analysis
This analysis method presupposes grouping objects into clusters based on their degree of similarity. The objects of the classification are observations. The latter may include consumers, countries, items, and others. So, the main goal of cluster analysis is to find groups of similar objects in a sample.
This method is widely used in many applications. These include market research, pattern recognition, and image processing. It can also help marketers discern distinct groups in their customer base.
Neural networks
This area of discipline lays the ground for the smart capabilities of machine learning. This analysis method aims to mimic the processing power of the human brain and predicts values with minimal involvement. Since neural networks learn from each and every data transaction, they evolve and improve over time. They are an indispensable predictive tool that is widely used in forecasting and marketing research to fraud detection and risk assessment.
Step 8: Visualization
Last but not least goes the graphical representation of the insights obtained. This step is usually amplified with visualization tools and can take the form of:

By visualizing the insights, you provide a digestible report that channels the message to a wider audience both inside and outside the organization. The report form may vary based on the nature of insights and the company.
It is not a mandatory step for all data projects. However, this stage is still important to close an effective data life cycle. The building block of a Big data strategy can differ based on the data complexity, business needs, and application area. Yet, these are the basic 8 steps of managing massive information layers.
The final word
Big data collection and analytics unlock a heap of unprecedented opportunities for organizations. They help make the most of the incoming facts and figures as well as identify growth areas. That, in turn, leads to intelligent business moves, more efficient processes, higher profits, and satisfied customers.
But to drive data intelligence, companies need to establish a consistent collection strategy. The latter involves multiple steps of gathering, cleansing, and analyzing the material. As a result, a well-maintained strategy transforms into a comprehensive data flywheel that ensures a self-reinforcing loop of business insights.
Data collection solutions by InData Labs
Need help with data collection and analysis? Shedule a call, and our specialists will consult you on best data collection methods for your project.


